此文档主要是针对第一章第一、二节的内容,包括对RAG的介绍及环境准备。 学习文档地址:All-in-RAG | 大模型应用开发实战:RAG技术全栈指南
什么是RAG?
Retrieval-Augmented Generation,字面意思,检索增强生成。
核心功能就是,在LLM生成文本之前,去外部知识库先获取知识,然后将结果融入到LLM的生成结果里面,提高准确性和时效性。
有哪些RAG?
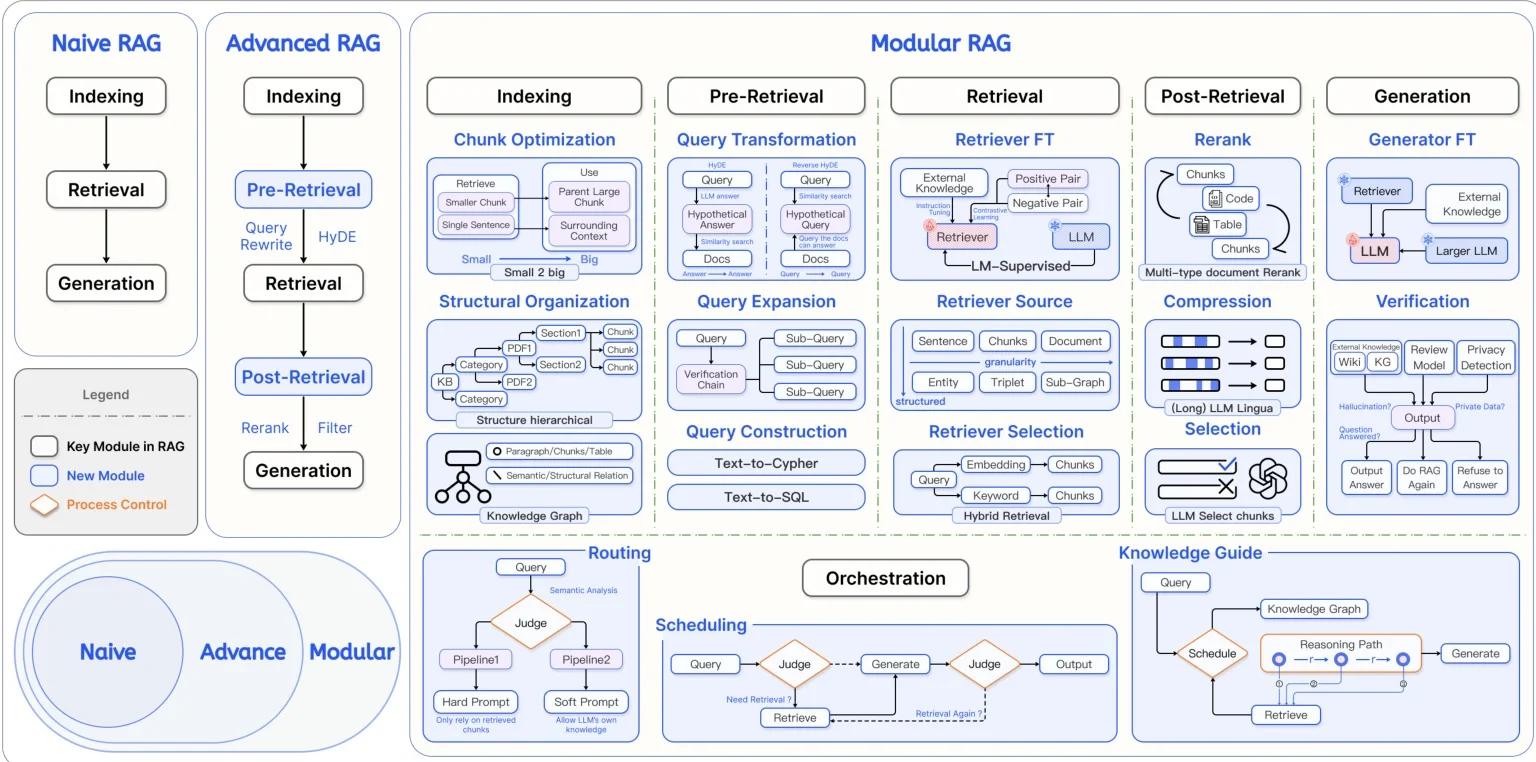
第一部分:Naive RAG (朴素/经典RAG)
这是最基础、最原始的RAG形态,可以看作是所有复杂RAG系统的起点。它包含三个核心步骤:
-
Indexing (索引):
- 做什么:这是准备知识库的过程。将你的文档(如PDF, TXT, HTML等)切分成小块(Chunks),然后通过一个嵌入模型(Embedding Model)将每个小块文本转换成一串数字,即向量(Vector)。
- 为什么:计算机不理解文字,但能处理数字。向量化之后,语义上相似的文本块在数学空间中的距离也会很近。这些向量最终被存入专门的向量数据库中。
-
Retrieval (检索):
- 做什么:当用户提出一个问题(Query)时,同样将这个问题也转换成一个向量。然后用这个查询向量去向量数据库里进行相似度搜索,找出与问题最相关的几个文本块(Chunks)。
- 为什么:目的是在庞大的知识库中,快速、准确地找到可能包含答案的“原始证据”。
-
Generation (生成):
- 做什么:将用户的原始问题和上一步检索到的相关文本块,一起打包“喂”给大语言模型(LLM)。
- 为什么:让LLM基于提供的上下文信息(检索到的文本块)来生成一个精准、有依据的回答,而不是仅仅依赖其内部的、可能过时或不相关的知识。
核心痛点:朴素RAG的效果高度依赖检索质量。如果第一步检索回来的内容不准或不相关,LLM也无能为力,这就是“垃圾进,垃圾出”(Garbage In, Garbage Out)。
第二部分:Advanced RAG (高级RAG)
为了解决朴素RAG的痛点,高级RAG在核心流程前后增加了“预处理”和“后处理”环节,像是在检索这个核心动作上加了“前后护法”。
-
Pre-Retrieval (检索前优化):
- 做什么:在拿着用户问题去检索之前,先对问题本身进行优化。
- 图中例子:
- Query Rewrite (查询重写):用LLM把用户模糊的、口语化的问题,改写成更适合机器检索的、更精确的查询语句。
- HyDE (假设性文档嵌入):一个有趣的技术。让LLM先针对问题“凭空”生成一个理想的答案,然后用这个虚构的理想答案的向量去做检索。因为理想答案和知识库里的真实答案在语义上可能更接近,所以有时效果更好。
-
Post-Retrieval (检索后优化):
- 做什么:从数据库里初步检索出一批内容后,不直接用,而是先进行筛选和排序。
- 图中例子:
- Rerank (重排序):初步检索(通常为了速度)可能不够精准。用一个更强大但更慢的模型(如 Cross-Encoder)对初步召回的几十个文本块进行重新打分排序,选出真正最相关的Top-K个。
- Filter (过滤):根据规则或模型过滤掉不相关、重复或低质量的文本块。
核心思想:通过在检索前后下功夫,提升送给LLM的上下文材料的“信噪比”,从而提高最终答案的质量。
第三部分:Modular RAG (模块化RAG)
这是当前RAG研究和应用的最前沿。它不再是一个固定的线性流程,而是将整个RAG系统拆分成一系列可以自由组合、替换和优化的“即插即用”模块。这提供了极大的灵活性。
图中将模块化RAG分为了几个关键阶段:
-
Indexing (索引模块):
- Chunk Optimization:精细化地设计切块策略,比如大块和小块结合、根据上下文关联切块等。
- Structural Organization:不仅仅是无脑切块,而是利用文档的结构(如标题、段落、表格)或构建知识图谱(Knowledge Graph)来组织信息。
-
Pre-Retrieval (检索前模块):
- Query Transformation:查询转换的方式更多样,比如分解复杂问题为子问题(Sub-Query)、将自然语言转为数据库查询语言(Text-to-SQL)等。
- Routing:这是一个“路由”模块,像一个聪明的调度员。它会判断用户的查询应该交给哪个处理流程或哪个知识库(例如,简单问题走朴素RAG,复杂问题走知识图谱路径)。
-
Retrieval (检索模块):
- Retriever FT (微调):对检索模型本身进行微调(Fine-Tuning),让它更适应特定领域的数据。
- Retriever Source / Selection:可以从多种数据源(向量库、关键词库、结构化数据库)进行检索,并智能选择或融合(Hybrid Search)多种检索方法。
-
Post-Retrieval (检索后模块):
- Rerank:同高级RAG,但模型和策略可以更复杂。
- Compression (压缩):在送给LLM前,对检索到的长文本进行智能压缩,提取核心信息,以适应LLM的上下文窗口限制。
- LLM Select Chunks:用一个LLM来判断哪些检索到的块是真正有用的。
-
Generation (生成模块):
- Generator FT (微调):对生成答案的LLM进行微调。
- Verification (验证):生成答案后,增加一个验证步骤。检查答案是否与检索到的原文一致(减少幻觉),或是否需要拒绝回答。
模块化RAG的“大脑”
图中底部还展示了两个更高层次的概念:
- Orchestration (编排):这是整个模块化RAG的“指挥官”。它负责根据用户问题和中间结果,动态地决定下一步调用哪个模块(Scheduling)、走哪条处理路径(Routing)。这通常由一个强大的LLM(图中的Judge)来决策。
- Knowledge Guide (知识引导):使用知识图谱来指导整个问答过程。对于需要多步推理的复杂问题,知识图谱可以提供一个清晰的“推理路径”,指导系统先检索什么、再检索什么,最后综合生成答案。
总结
这张图告诉我们:
- 演进方向:RAG正从一个简单的“检索+生成”流程,演变为一个复杂、智能、可自适应的系统。
- 核心趋势:模块化和智能化。每个环节都变成可优化的模块,并引入LLM来做决策和调度(Routing, Judge, Scheduling),让RAG系统本身变得“会思考”。
- 最终目标:无限逼近一个理想状态——为大语言模型提供最精准、最全面、最精炼的上下文信息,让它能够回答任何基于特定知识库的复杂问题。
为什么要RAG?
| 问题 | RAG的解决方案 |
|---|---|
| 静态知识局限 | 实时检索外部知识库,支持动态更新 |
| 幻觉(Hallucination) | 基于检索内容生成,错误率降低 |
| 领域专业性不足 | 引入领域特定知识库(如医疗/法律) |
| 数据隐私风险 | 本地化部署知识库,避免敏感数据泄露 |
如何上手RAG?
RAG (检索增强生成) 技术栈概览
| 类别 (Category) | 工具 / 模型 (Tool / Model) | 核心特点与适用场景 |
|---|---|---|
| 应用编排框架 | LangChain | 功能最全的“瑞士军刀”,生态庞大,灵活性高。适合快速原型和复杂应用。 |
| LlamaIndex | 专注于数据的索引与检索优化,处理复杂文档能力强。 | |
| Haystack | 注重生产环境,工程化设计,提供端到端的健壮流水线。 | |
| Semantic Kernel | 微软出品,与C#/Python结合紧密,更贴近传统软件开发模式。 | |
| 嵌入模型 | OpenAI Embeddings | text-embedding-3-large等,性能强大,使用简单的API。 |
| Cohere Embeddings | 在多个评测基准上表现突出,提供高质量的向量表示。 | |
| 开源模型 (BGE, M3E等) | Hugging Face上可用,中英双语效果好,免费且可控,适合私有化部署。 | |
| 向量数据库 | Pinecone | 商业化的向量数据库先驱,性能优异,完全托管的云服务。 |
| Milvus | 功能强大的开源标准,支持大规模部署,同时提供云服务选项。 | |
| Faiss | FaceBook开源的高效向量库,专门用于大规模数据的相似性搜索和聚类。 | |
| RAG评估框架 | RAGAs | 从答案忠实度、相关性等多个维度对RAG系统进行自动化打分。 |
| TruLens | 提供RAG应用内部运作的“可观测性”,帮助调试和理解系统行为。 |
四步构建最小可行系统(MVP)
环境部署
学习文档地址:第二节 准备工作
在个人PC上准备环境,使用Ollama本地大模型,不再赘述。
- 克隆代码
git clone https://github.com/datawhalechina/all-in-rag.git
- 本地使用
uv创建虚拟环境,并激活
uv venv -p python3.12.7 .venv
.venv\Scripts\activate
- 安装依赖包
uv pip install -r .\code\requirements.txt