学习文档地址 第三节 四步构建RAG
运行示例代码
笔者根据本地环境实际情况,修改了几个部分
- 调整hf的镜像
# hugging face镜像设置,如果国内环境无法使用启用该设置
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
- 嵌入模型时,使用本地GPU
# 中文嵌入模型, 使用GPU
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cuda'},
encode_kwargs={'normalize_embeddings': True}
)
- 大模型使用本地模型
from langchain_ollama import ChatOllama
# 配置大语言模型, 使用本地Ollama配置的 gemma3:4b 的量化模型
llm = ChatOllama(
base_url="http://127.0.0.1:11434",
model="gemma3-4b:Q4_K_M",
temperature=0.7
)
- 格式化最后输出
answer = llm.invoke(prompt.format(question=question, context=docs_content))
# 替换\n
print(answer.content.replace("\\n", "\n"))
一些踩坑
pyarrow的版本问题
AttributeError: module 'pyarrow' has no attribute 'PyExtensionType'. Did you mean: 'ExtensionType'?
降低
uv pip install pyarrow==20.0.0
详见 Python 21.0.0 Removes Attribute PyExtensionType · Issue #47155 · apache/arrow
- 模型路径问题
在
HuggingFaceEmbeddings这里,模型下载一直报错,开始以为是路径问题,所以手动更换了缓存路径。但是发现并不是路径问题,而是在windows下,对软链接的访问似乎有问题。
OSError: [Errno 22] Invalid argument: 'C:\\Users\\xxx\\.cache\\huggingface\\hub\\models--BAAI--bge-small-zh-v1.5\\snapshots\\7999e1d3359715c523056ef9478215996d62a620\\.\\config_sentence_transformers.json'
解决方案
- 使用管理员模式运行代码;
- 在【设置】-【系统】-【开发者选项】,打开【开发人员模式】,然后重启;
- 我也使用了环境变量,让hf禁用软链接,但是似乎未生效;
# os.environ['HF_HUB_DISABLE_SYMLINKS_WARNING'] = '1'
总结:Windows的环境很蛋疼,遇事不决先重启,包括但不限于终端、IDE、网络、机器;
实际效果
可以看到,成功从文档中获取到了信息,但是碍于gemma3:4b模型,并没有完全抓到所有例子,在前文还有一些关于强化学习的例子。这只能说明模型的能力问题,毕竟只有4b,从RAG的工作流来说是没有问题的,能够正确从向量库中获取到相关信息。
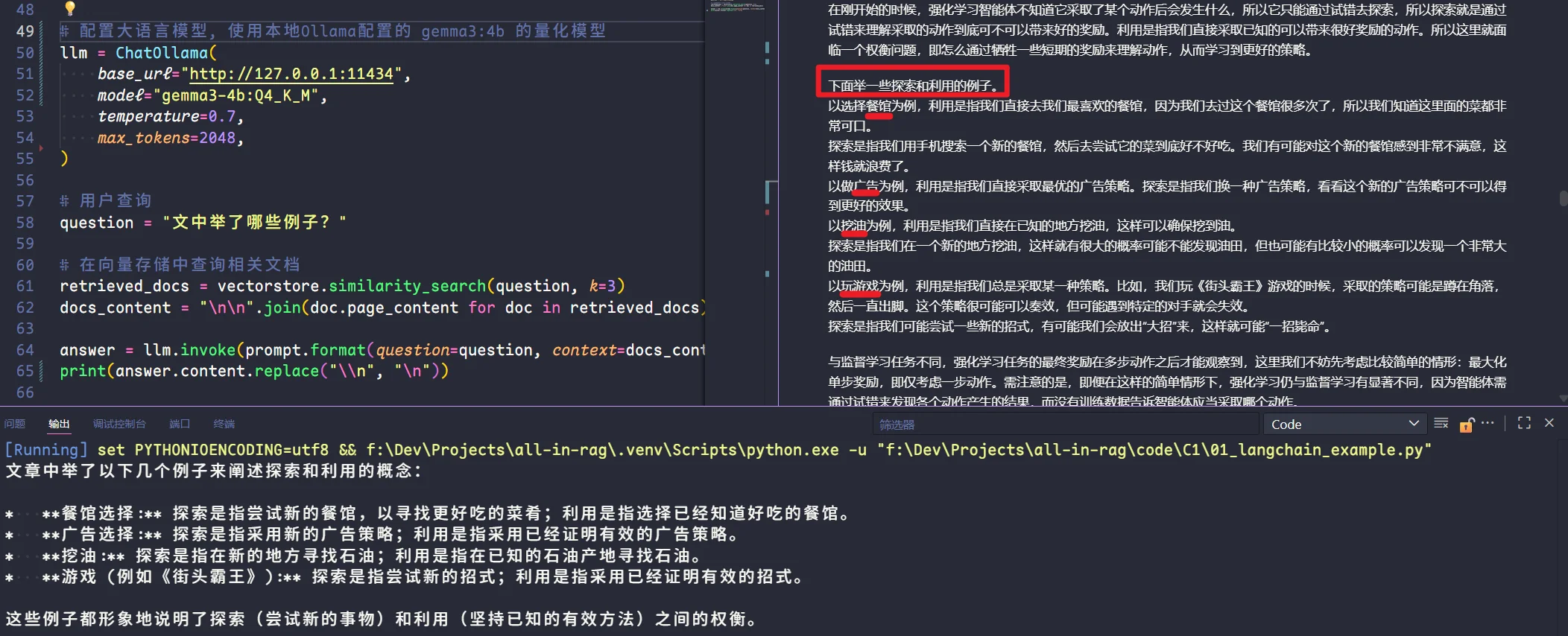
- 其他信息输出如下
ADDITIONAL_KWARGS
additional_kwargs={} # 额外参数
RESPONSE_METADATA
response_metadata = {
"model": "gemma3-4b:Q4_K_M", # 模型名称
"created_at": "2025-08-16T09:57:03.6623792Z", # 创建时间
"done": True, # 完成状态
"done_reason": "stop", # 终止原因,stop表示正常完成
"total_duration": 5196768900, # 整体耗时,包含加载模型、提示词等
"load_duration": 35969500, # 模型加载耗时
"prompt_eval_count": 4096, # 提示词Token数量
"prompt_eval_duration": 3484987200, # 模型处理提示词Token使用时长
"eval_count": 144, # 生成响应耗费Token数量
"eval_duration": 1675248700, # 模型生成响应耗费时长
"model_name": "gemma3-4b:Q4_K_M", # 模型名称
}
ID
# 本次运行的唯一标识符。
id='run--78462508-fcbd-41a1-925c-256268a9d7ea-0'
USAGE_METADATA
# Token使用量情况
usage_metadata={
"input_tokens": 4096, # 输入Token数量
"output_tokens": 144, # 输出Token数量
"total_tokens": 4240 # 整体Token数量
}
低代码实现
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 加载环境变量
load_dotenv()
# 设置LlamaIndex的配置,使用本地Ollama大模型
Settings.llm = Ollama(
model="gemma3-4b:Q4_K_M", base_url="http://127.0.0.1:11434", request_timeout=150
)
# 设置嵌入模型,使用HuggingFace的BGE小模型
Settings.embed_model = HuggingFaceEmbedding("BAAI/bge-small-zh-v1.5")
# 读取Markdown文件并创建索引
docs = SimpleDirectoryReader(
input_files=["../../data/C1/markdown/easy-rl-chapter1.md"]
).load_data()
# 创建向量存储索引
index = VectorStoreIndex.from_documents(docs)
# 索引查询引擎
query_engine = index.as_query_engine()
# 打印索引的提示词
print(query_engine.get_prompts())
print("--" * 20)
# 执行查询并打印结果
print(query_engine.query("文中举了哪些例子?用中文回答。"))
运行结果分析
1. 文本问答模板 (text_qa_template)
类型: SelectorPromptTemplate
用途: 基于提供的上下文信息回答用户查询
-
模板变量
-
context_str: 上下文信息 -
query_str: 用户查询 -
默认模板内容
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {query_str}
Answer:
- 条件模板 (聊天模型) 当检测到使用聊天模型时,会切换到以下模板:
系统消息
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information,
and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context,
...' or 'The context information ...'
or anything along those lines.
用户消息
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {query_str}
Answer:
2. 答案优化模板 (refine_template)
类型: SelectorPromptTemplate
用途: 基于新提供的上下文信息优化现有答案
- 模板变量
query_str: 原始查询existing_answer: 现有答案context_msg: 新的上下文信息
默认模板内容
The original query is as follows: {query_str}
We have provided an existing answer: {existing_answer}
We have the opportunity to refine the existing answer (only if needed) with some more context below.
------------
{context_msg}
------------
Given the new context, refine the original answer to better answer the query. If the context isn't useful, return the original answer.
Refined Answer:
- 条件模板 (聊天模型) 当检测到使用聊天模型时,会切换到以下模板:
用户消息
You are an expert Q&A system that strictly operates in two modes when refining existing answers:
1. **Rewrite** an original answer using the new context.
2. **Repeat** the original answer if the new context isn't useful.
Never reference the original answer or context directly in your answer.
When in doubt, just repeat the original answer.
New Context: {context_msg}
Query: {query_str}
Original Answer: {existing_answer}
New Answer:
3. 实际模型输出效果
文中举了以下例子:
**餐厅选择:** 利用是指去最喜欢的餐馆,因为知道那里菜很好;探索是指用手机搜索新餐馆并尝试。
**广告投放:** 利用是指采取最优的广告策略;探索是指换一种广告策略。
**油田开采:** 利用是指在已知有油的地方开采;探索是指在新的地方开采。
**玩游戏:** 比如玩《街头霸王》游戏,总是采取一个策略,比如蹲在角落然后出脚。
练习
练习1
修改Langchain代码中
RecursiveCharacterTextSplitter()的参数chunk_size和chunk_overlap,观察输出结果有什么变化。
- chunk_size=1000, chunk_overlep=200
根据上下文,文中举了以下例子:
* **餐馆选择:** 探索新的餐馆和利用已经熟悉的餐馆。
* **广告策略:** 尝试新的广告策略和利用最优广告策略。
* **油田挖掘:** 直接在已知地点挖油和在新的地点挖油。
* **玩游戏(《街头霸王》):** 采用特定策略,并尝试新的招式。
* **象棋:** 赢棋获得正奖励,输棋获得负奖励。
* **股票管理:** 奖励由股票获取的奖励与损失决定。
* **雅达利游戏:** 奖励是增加或减少的游戏分数。
* **MountainCar-v0 游戏:** 智能体控制小车移动,通过 Gym 库进行交互。
- chunk_size=1000, chunk_overlap=500
文中所举的例子包括:
* **DeepMind 的走路智能体**:这个智能体通过举手来保持平衡,并能抵抗环境扰动。
* **机械臂抓取**:使用多个机械臂进行训练,以学习统一的抓取算法,适用于不同形状的物体。
* **OpenAI 的机械臂翻魔方**:先在虚拟环境中训练智能体,再应用到真实的机械臂上。
* **穿衣智能体**:训练智能体来实现穿衣功能。
* **走迷宫的例子**:智能体从起点到达终点,每走一步获得 -1 的奖励。
* **选择餐馆的例子**:利用是指直接去最喜欢的餐馆,探索是指搜索新的餐馆。
* **玩游戏《街头霸王》的例子**:利用是指一直出脚,探索是指使用“大招”。
- chunk_size=1000, chunk_overlap=1000
文章中举了以下例子:
* **DeepMind 的走路智能体:** 学习在曲折道路上走路,并发现举手可以保持平衡,从而更快前进。
* **机械臂抓取:** 使用多个机械臂进行训练,学习抓取不同形状的物体,并可以针对不同物体使用最优抓取算法。
* **OpenAI 的机械臂翻魔方:** 先在虚拟环境训练智能体,再应用到真实的机械臂上,最后改进后可以玩魔方。
* **穿衣智能体:** 训练智能体实现穿衣功能,并可以抵抗扰动。
* **雅达利游戏 Breakout:** 一个打砖块的游戏,展示了强化学习的挑战性,因为智能体无法获得即时的反馈,且观测数据不是独立同分布的。
希望这个回答对您有帮助!
- chunk_size=2000, chunk_overlap=0
文中所举的例子包括:
* **OpenAI 的机械臂翻魔方:** 训练智能体在虚拟环境中学习如何通过手指动作来控制木块。
* **穿衣服的智能体:** 训练智能体学习穿衣服的精细操作。
* **雅达利游戏 Breakout:** 通过控制木板来击打砖块的游戏,用于说明延迟奖励和探索与利用之间的权衡。
* **MountainCar-v0 例子:** 一个简单的上山任务,用于展示智能体与环境的交互,以及如何定义观测空间和动作空间。
- chunk_size=2000, chunk_overlap=200
文章中举了以下例子:
1. **餐馆选择:** 利用是指去自己喜欢的餐馆,因为熟悉且知道菜品好;探索是指搜索新的餐馆并尝试。
2. **广告策略:** 利用是指采用最优的广告策略;探索是指换一种广告策略。
3. **挖油:** 利用是指在已知地点挖油;探索是指在新的地点挖油。
4. **玩游戏(Breakout):** 举例说明了打砖块游戏,以及智能体需要尝试不同的动作,并等待游戏结束才能知道哪些动作是有效的。
5. **机械臂翻魔方:** OpenAI 设计的机械臂,先在虚拟环境训练,再应用到真实机械臂上。
6. **穿衣服的智能体:** 训练智能体穿衣服,并加入扰动测试。
7. **雅达利游戏 Breakout:** 作为一个具体的例子来说明强化学习的训练过程,强调了延迟奖励和探索-利用困境。
8. **OpenAI 的 Gym 库:** 包括雅达利游戏 Breakout、Pong 游戏、机械臂翻魔方和穿衣服的智能体等环境。
9. **OpenAI 的机械臂:** 用于翻魔方的机器人。
总而言之,文章通过一系列具体的例子,说明了强化学习与监督学习的区别,并阐述了探索-利用困境。
- chunk_size=2000, chunk_overlap=500
根据上下文,文中举了以下例子:
1. **象棋选手**: 输赢棋局的奖励。
2. **股票管理**: 根据股票获取的奖励与损失来确定奖励。
3. **雅达利游戏**: 通过增加或减少游戏分数来确定奖励。
4. **走迷宫**: 奖励为每走一步 -1。
5. **MountainCar**: 智能体控制小车移动,并根据环境反馈给予奖励。
此外,文中还提到了强化学习智能体的类型,包括基于价值的智能体和基于策略的智能体,以及有模型强化学习智能体和免模型强化学习智能体。
练习1总结
我将上述测试结果形成表格,统计不同参数对结果的影响,可以看出,并不是两个参数越大越好或者越小越好,不同的搭配会有不同的效果。
概述
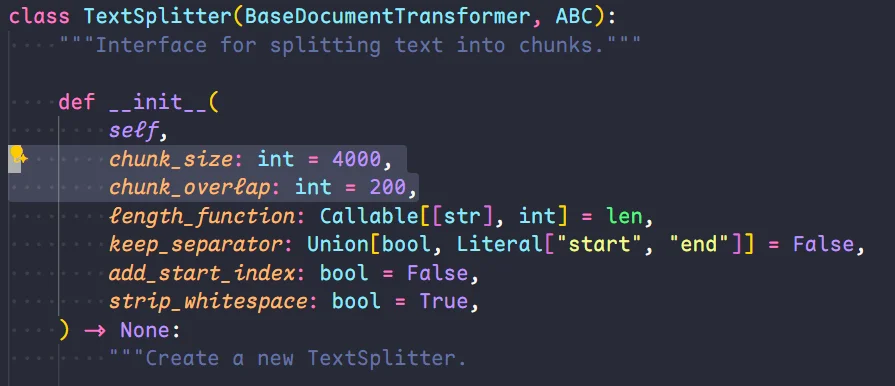
chunk_size是定义每个文本块(chunk)的最大长度。即每个块需要多大,size越大,每个块包含的内容也就越多,LLM返回的信息也会越多,但可能精度不够;如果太小,则信息会比较零散;chunk_overlap是定义了相邻两个文本块之间字符的重复量,缓解上下文的碎片化问题。overlap越大,上下文的关联性也会越强,但是可能会造成重复信息;但如果太小,则会造成语义丢失,因为上下文的关联性几乎没有了。- 查看源码可知,
size的默认值是4000,overlap的默认值是200; - 一般来说,
size的设置为1000-2000,overlap则设定为size的10%-20%,太大会造成多数重复信息,且浪费token; - 详细的讲解内容会在后续章节进行说明;
练习2
- LangChain代码最终得到的输出携带了各种参数,查询相关资料尝试把这些参数过滤掉得到
content里的具体回答。
回答
print(answer.content.replace("\\n", "\n"))
练习3
- 给LlamaIndex代码添加代码注释。
- 详见02-get-start-rag#低代码实现