学习文档地址 第二章
数据加载
文档加载器
文档加载器,顾名思义,即将各类不同格式的数据文档转换为程序可处理的结构化文档,加载器的好会啊会直接影响后续的索引构建和检索效果。
主要功能:
- 文档格式解析 将不同格式的文档(如PDF、Word、Markdown等)解析为文本内容。
- 元数据提取 在解析文档内容的同时,提取相关的元数据信息,如文档来源、页码等。
- 统一数据格式 将解析后的内容转换为统一的数据格式,便于后续处理。
主流RAG文档加载器
| 工具名称 | 特点 | 适用场景 | 性能表现 |
|---|---|---|---|
| PyMuPDF4LLM | PDF→Markdown转换,OCR+表格识别 | 科研文献、技术手册 | 开源免费,GPU加速 |
| TextLoader | 基础文本文件加载 | 纯文本处理 | 轻量高效 |
| DirectoryLoader | 批量目录文件处理 | 混合格式文档库 | 支持多格式扩展 |
| Unstructured | 多格式文档解析 | PDF、Word、HTML等 | 统一接口,智能解析 |
| FireCrawlLoader | 网页内容抓取 | 在线文档、新闻 | 实时内容获取 |
| LlamaParse | 深度PDF结构解析 | 法律合同、学术论文 | 解析精度高,商业API |
| Docling | 模块化企业级解析 | 企业合同、报告 | IBM生态兼容 |
| Marker | PDF→Markdown,GPU加速 | 科研文献、书籍 | 专注PDF转换 |
| MinerU | 多模态集成解析 | 学术文献、财务报表 | 集成LayoutLMv3+YOLOv8 |
从上表可以看出,有些加载器是专门加载某一单一类型文档的,例如PyMuPDF4LLM就只用于处理PDF文档;而有些则是照单全收,例如Unstructured基本涵盖所有文档类型。
All-in-RAG教程推荐使用 Unstructured 进行文档加载,因为它提供了统一的接口来处理多种文档格式,处理方便。
Unstructured加载器
核心优势
格式支持广泛
- 支持多种文档格式:PDF、Word、Excel、HTML、Markdown等;
- 统一的API接口,无需为不同格式编写不同代码;
智能内容解析
- 自动识别文档结构:标题、段落、表格、列表等;
- 保留文档元数据信息,具体元数据信息如下表所示;
| 元素类型 | 描述 |
|---|---|
Title | 文档标题 |
NarrativeText | 由多个完整句子组成的正文文本,不包括标题、页眉、页脚和说明文字 |
ListItem | 列表项,属于列表的正文文本元素 |
Table | 表格 |
Image | 图像元数据 |
Formula | 公式 |
Address | 物理地址 |
EmailAddress | 邮箱地址 |
FigureCaption | 图片标题/说明文字 |
Header | 文档页眉 |
Footer | 文档页脚 |
CodeSnippet | 代码片段 |
PageBreak | 页面分隔符 |
PageNumber | 页码 |
UncategorizedText | 未分类的自由文本 |
CompositeElement | 分块处理时产生的复合元素 |
实际使用
在第一章的代码示例中,我们使用的是from langchain_community.document_loaders import UnstructuredMarkdownLoader,是LangChain对Unstructured库的封装。接下来看看原始库的使用方式;
from unstructured.partition.auto import partition
# PDF文件路径
# 这是一个html页面转的PDF,内容是百度百科"检索增强生成"的词条信息
pdf_path = "../../data/C2/pdf/rag.pdf"
# 使用Unstructured加载并解析PDF文档,核心步骤
elements = partition(
filename=pdf_path,
content_type="application/pdf"
)
# 打印解析结果
print(f"解析完成: {len(elements)} 个元素, {sum(len(str(e)) for e in elements)} 字符")
# 统计元素类型
from collections import Counter
types = Counter(e.category for e in elements)
print(f"元素类型: {dict(types)}")
# 显示所有元素
print("\n所有元素:")
for i, element in enumerate(elements, 1):
print(f"Element {i} ({element.category}):")
print(element)
print("=" * 60)
从PDF文档中解析出了279个元素,共计7500字符。从下图也可以看出,基本上是把每一个小块都完整的解析了出来。
解析完成: 279 个元素, 7500 字符
元素类型: 'Header': 22, 'Title': 195, 'UncategorizedText': 41, 'NarrativeText': 3, 'Footer': 15, 'ListItem': 3

代码解析
上述代码的核心步骤,在于 partiton 这一步。我们点进去,可以看到这个函数的定义,具体如下:
def partition(
filename: Optional[str] = None, # 文档路径
*,
file: Optional[IO[bytes]] = None, # 文档IO格式
encoding: Optional[str] = None, # 编码格式
content_type: Optional[str] = None, # 文档类型,默认会自动识别
url: Optional[str] = None, # 在线地址
headers: dict[str, str] = {}, # 使用在线URL时定义Hearders
ssl_verify: bool = True, # 使用在线地址时是否使用SSL
request_timeout: Optional[int] = None, # 使用在线地址时的反应最大时长
strategy: str = PartitionStrategy.AUTO, # 处理策略,可选"auto"、"fast"、"hi_res"等
skip_infer_table_types: list[str] = ["pdf", "jpg", "png", "heic"], # 要跳过表提取的文档类型。
ocr_languages: Optional[str] = None, # OCR识别的语言选项
languages: Optional[list[str]] = None, # 文档语言
detect_language_per_element: bool = False, # 元素级别的语言自动识别,而不是根据整个文档的语言
pdf_infer_table_structure: bool = False, # 已失效
extract_images_in_pdf: bool = False, # 仅在strategy=hi_res模式下可用,会从PDF中提取图片到指定位置
extract_image_block_types: Optional[list[str]] = None,
extract_image_block_output_dir: Optional[str] = None,
extract_image_block_to_payload: bool = False,
data_source_metadata: Optional[DataSourceMetadata] = None,
metadata_filename: Optional[str] = None, # metadata存储文件名
hi_res_model_name: Optional[str] = None, # hi_res的模型名称
model_name: Optional[str] = None, # to be deprecated
starting_page_number: int = 1, # 开始页码
**kwargs: Any,
) -> list[Element]:
练习
使用
partition_pdf替换当前partition函数并分别尝试用hi_res和ocr_only进行解析,观察输出结果有何变化。
hi_res模式
elements = partition(
strategy="hi_res",
filename=pdf_path,
content_type="application/pdf",
languages=["zh"],
)
遇到问题
- 本地环境没有安装
popplerpdf2image.exceptions.PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?- 需要手动安装
poppler软件,让其调用;
- 需要手动安装
- 本地环境没有安装
tesseractOCR- 前往官方地址/tesseract Wiki进行下载安装;
- 上述环境安装完成后,要将其加入到环境变量才能生效;
解析完成: 234 个元素, 8267 字符
元素类型: 'Image': 21, 'UncategorizedText': 99, 'Header': 4, 'NarrativeText': 68, 'Table': 4, 'FigureCaption': 4, 'Title': 30, 'ListItem': 4
可以看出,比auto的解析结果少了一些元素,但是整体字符多了很多;其次,元素类型也有区别;
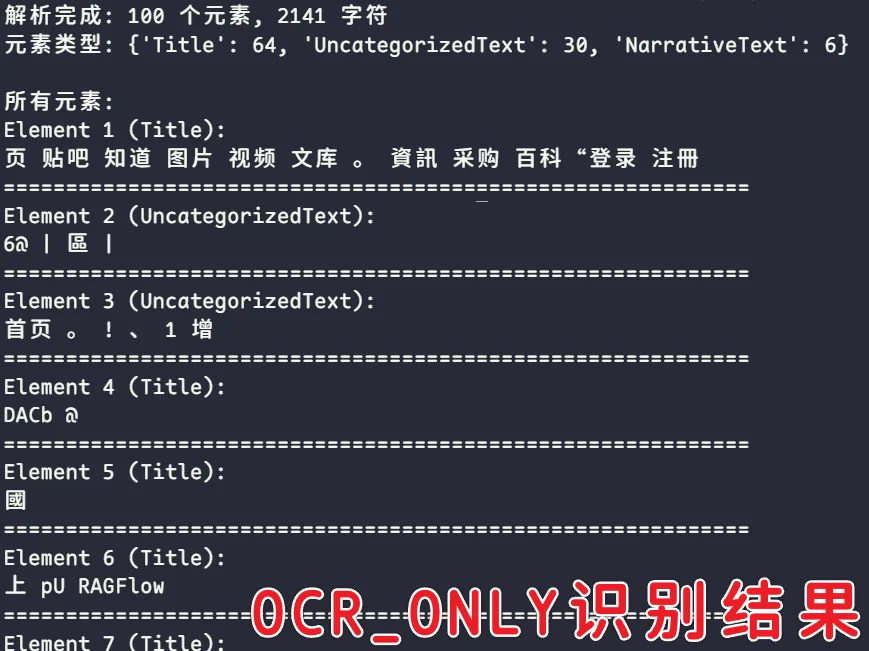
ocr_only模式
解析完成: 100 个元素, 2141 字符
元素类型: 'Title': 64, 'UncategorizedText': 30, 'NarrativeText': 6
ocr_only解析出来的元素和字符是最少的,且内容识别结果正确也较差,可见下图
结果对比
- fast模式最快,一般情况auto对简单文本采用的就是fast模式,不依赖OCR也不提取图像;
- hi_res`模式最全面,会提取图像、表格,也需要更多的环境支持;
- ocr_only只采用OCR进行文字提取,对文档的质量要求较高,识别出来的字符数最少;
| 元素类型 | hi_res | ocr_only | fast |
|---|---|---|---|
| Title | 30 | 64 | 195 |
| Image | 21 | - | - |
| UncategorizedText | 99 | 30 | 41 |
| Headers | 4 | - | 22 |
| NarrativeText | 68 | 6 | 3 |
| Table | 4 | - | - |
| FigureCaption | 4 | - | - |
| ListItem | 4 | - | 3 |
| Footer | - | - | 15 |
| 字符数量 | 8267 | 2141 | 7500 |
文本分块
文本分块是RAG的基石,文本分块的质量,直接决定了RAG最终系统回答质量的上限。这些被切分出的文本块,是后续向量检索和模型处理的基本单位。
文本分块重要性
- 满足两个模型(嵌入模型、大语言模型)的上下文限制,不能超出;
- 块过大的弊处:
- 向量化嵌入的时候会丢失信息,语义会被稀释;
- LLM无法从大块文件有效检索到所需信息,造成幻觉;
- 主题被稀释,无法精确检索;
分块策略
Langchain提供了多种文本分割器(Text Splitters).
CharacterTextSplitter (字符分割器)
也称固定大小分割,最简单直接的分块方法,通过指定的分隔符进行分割。默认的分隔符是\n\n。
分割完成后会智能合并,如果两个或者多个分块整体的长度没有超过chunk_size,则会合并成一个分块。如果超过了,也不会强制分割,而是进行提示,同时保留这个超长的分块。
RecursiveCharacterTextSplitter (递归字符分割器)
与CharacterTextSplitter的区别是——递归,会根据有效分隔符来进行遍历:
- 寻找有效分隔符: 从分隔符列表中从前到后遍历,找到第一个在当前文本中存在的分隔符。如果都不存在,使用最后一个分隔符(通常是空字符串
"")。 - 切分与分类处理: 使用选定的分隔符切分文本,然后遍历所有片段:
- 如果片段不超过块大小: 暂存到
_good_splits中,准备合并 - 如果片段超过块大小:
- 首先,将暂存的合格片段通过
_merge_splits合并成块 - 然后,检查是否还有剩余分隔符:
- 有剩余分隔符: 递归调用
_split_text继续分割 - 无剩余分隔符: 直接保留为超长块
- 有剩余分隔符: 递归调用
- 首先,将暂存的合格片段通过
- 如果片段不超过块大小: 暂存到
- 最终处理: 将剩余的暂存片段合并成最后的块
SemanticChunker(语义分块器)
在语义主题发生显著变化的地方进行切分。这使得每个分块都具有高度的内部语义一致性。 核心逻辑:
- 先对句子进行切割
- 上下文向量化(Embedding)
- 计算语义距离——余弦距离(Cosine Distance)
- 识别断点——根据距离值进行切分
- 合并成块 优劣都比较明显,优点是语义相关性极高,缺点也很明显,即需要花费额外算力进行向量化;
MarkdownHeaderTextSplitter (Markdown 标题分割器)
专门针对md文档的分割,不依靠长度,而是根据标题层级来进行划分。优点是能够很好的识别段落结构,缺点是只对MD有效;
CodeTextSplitter (代码分割器)
顾名思义,这是为源代码设计的分割器。它支持多种编程语言(Python, JavaScript, Java, C++ 等),并会尝试根据语言的语法结构(如函数、类、注释块)来寻找合适的分割点。
TokenTextSplitter (Token 分割器)
它使用一个 tiktoken (OpenAI 使用的库) 或其他分词器(tokenizer)来计算文本的 Token 数量,并确保每个块的 Token 数不超过 chunk_size。
精确控制成本和上下文窗口:LLM 的计费和输入限制都是基于 Token 的。使用这个分割器,你可以非常精确地知道每个块的大小,从而更好地管理 API 成本和避免超出模型的上下文长度限制。
Unstructured:基于文档元素的智能分块
在前文提到了Unstructured加载器,加载文档时,会将文档中的多个元素识别出来,包括标题、段落、列表等——这就是分区功能(Partition); 在分区的基础上,会对文本进行分块(Chunking),将识别出来的元素进行智能组合。 Unstructured 允许将分块作为分区的一个参数在单次调用中完成,也支持在分区之后作为一个独立的步骤来执行分块。这种“先理解、后分割”的策略,使得 Unstructured 能在最大程度上保留文档的原始语义结构,特别是在处理版式复杂的文档时,优势尤为明显。
LlamaIndex:面向节点的解析与转换
将数据流抽象为节点(Node),Node 是 LlamaIndex 的基本原子单位,它比一个简单的文本块要丰富得多。一个Node对象除了包含文本(text)和元数据(metadata)外,最关键的是还包含关系信息(relationships),比如它与父节点、子节点、前一个节点、后一个节点的关系。
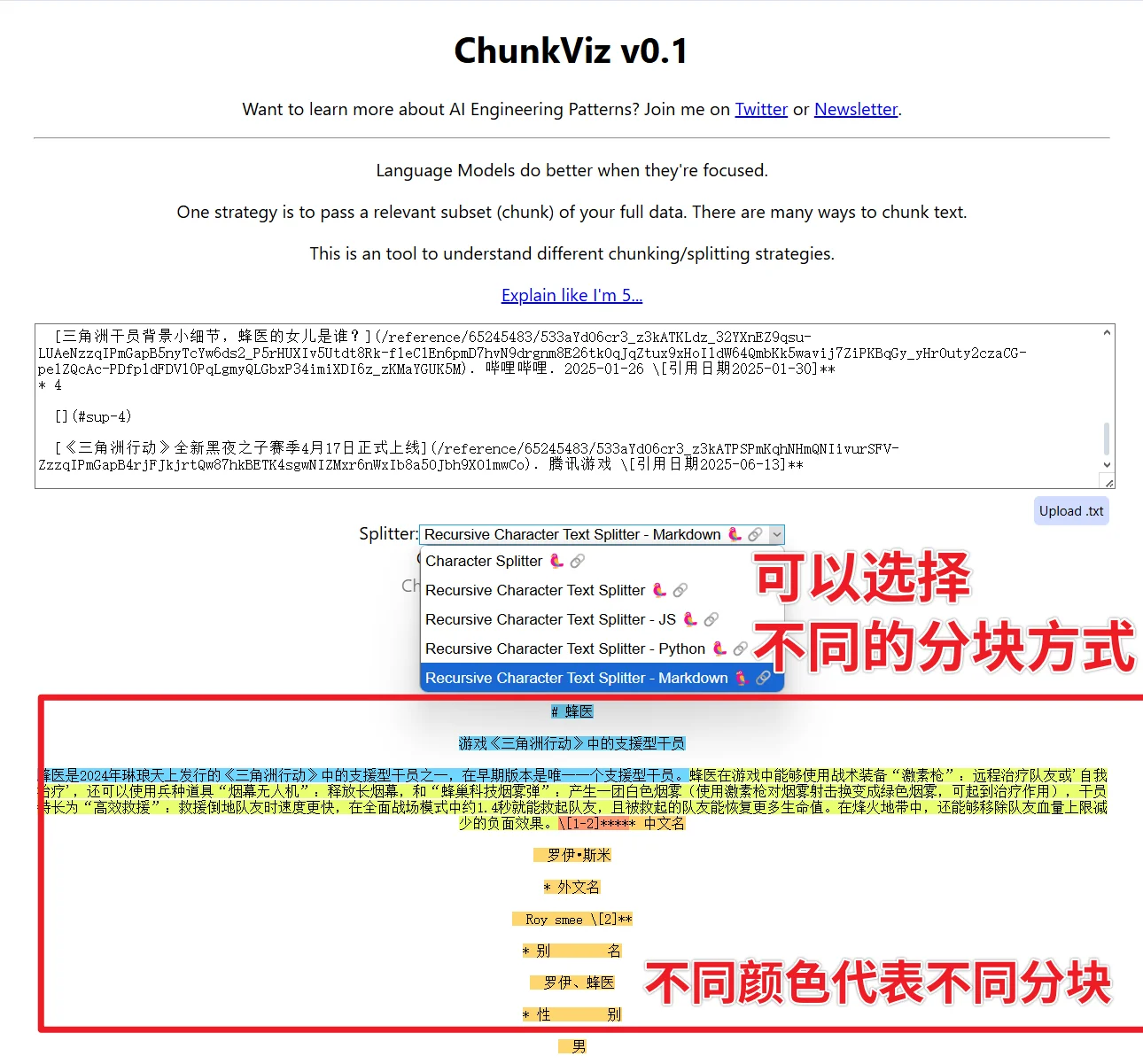
ChunkViz:简易的可视化分块工具
ChunkViz 可以将你的文档、分块配置作为输入,用不同的颜色块展示每个 chunk 的边界和重叠部分,方便快速理解分块逻辑。