学习文档地址 第三章 1、2节
基础概念
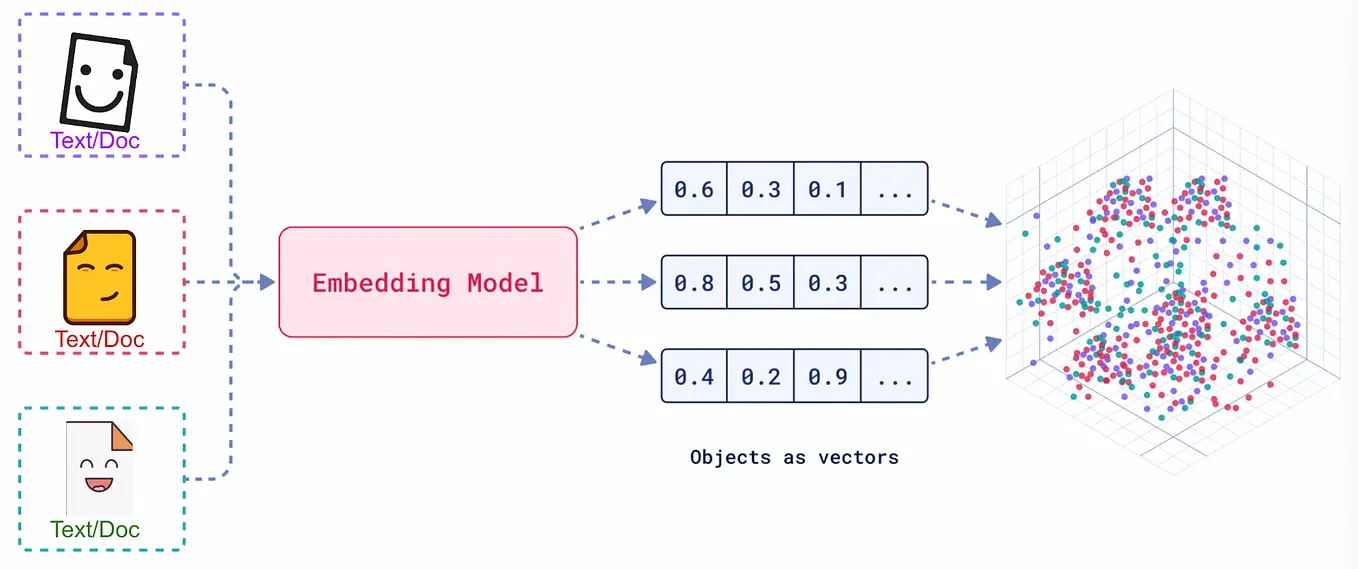
向量嵌入(Embedding)是一种将真实世界中复杂、高维的数据对象(如文本、图像、音频、视频等)转换为数学上易于处理的、低维、稠密的连续数值向量的技术。
核心重点
将高维真实对象转为多维数据向量;
通过计算数据向量之间的向量距离,判断语义是否相近;
技术发展
训练原理
模型选择
查看MTEB (Massive Text Embedding Benchmark) ,是一个由 Hugging Face 维护的、全面的文本嵌入模型评测基准。它涵盖了分类、聚类、检索、排序等多种任务,并提供了公开的排行榜,为评估和选择嵌入模型提供了重要的参考依据。
多模态嵌入
多模态就是将不同类型的数据(图片、文本、音视频等),映射到同一个共享的向量空间;
CLIP
OpenAI 的 CLIP (Contrastive Language-Image Pre-training) 是一个很有影响力的模型,它为多模态嵌入定义了一个有效的范式。
- 包含两个独立编码器:图像+文本;
- 训练时采用对比学习策略,会同时处理一张图片和一批文本描述(其中一个是正确的,其余都是错误的),以此来使得正确的图片-文本对生成的向量在空间中尽可能接近,而错误的图片-文本对的向量则尽可能远离;
- 具有零样本能力,CLIP 无需针对特定任务进行微调,就能实现对视觉概念的泛化理解;
BEM-M3
由北京智源人工智能研究院(BAAI)开发的 BGE-M3 是一个很有代表性的现代多模态嵌入模型;
- 多语言性 (Multi-Linguality):原生支持超过 100 种语言的文本与图像处理,能够轻松实现跨语言的图文检索。
- 多功能性 (Multi-Functionality):在单一模型内同时支持密集检索(Dense Retrieval)、多向量检索(Multi-Vector Retrieval)和稀疏检索(Sparse Retrieval),为不同应用场景提供了灵活的检索策略。
- 多粒度性 (Multi-Granularity):能够有效处理从短句到长达 8192 个 token 的长文档,覆盖了更广泛的应用需求。
代码示例
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
model = Visualized_BGE(model_name_bge="BAAI/bge-base-en-v1.5",
model_weight=r"./Visualized_base_en_v1.5.pth")
model.eval()
with torch.no_grad():
# 纯文本嵌入
text_emb = model.encode(text="datawhale开源组织的logo")
# 纯图像嵌入
img_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png")
# 文本+图像嵌入
multi_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png", text="datawhale开源组织的logo")
# 纯图像嵌入2
img_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png")
# 文本+图像嵌入2
multi_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png", text="datawhale开源组织的logo")
# 计算相似度
sim_1 = img_emb_1 @ img_emb_2.T
sim_2 = img_emb_1 @ multi_emb_1.T
sim_3 = text_emb @ multi_emb_1.T
sim_4 = multi_emb_1 @ multi_emb_2.T
print("=== 相似度计算结果 ===")
print(f"纯图像 vs 纯图像: {sim_1}")
print(f"图文结合1 vs 纯图像: {sim_2}")
print(f"图文结合1 vs 纯文本: {sim_3}")
print(f"图文结合1 vs 图文结合2: {sim_4}")
# 向量信息分析
print("\n=== 嵌入向量信息 ===")
print(f"多模态向量维度: {multi_emb_1.shape}")
print(f"图像向量维度: {img_emb_1.shape}")
print(f"多模态向量示例 (前10个元素): {multi_emb_1[0][:10]}")
print(f"图像向量示例 (前10个元素): {img_emb_1[0][:10]}")
=== 相似度计算结果 ===
纯图像 vs 纯图像: tensor([[0.8318]], device='cuda:0')
图文结合1 vs 纯图像: tensor([[0.8291]], device='cuda:0')
图文结合1 vs 纯文本: tensor([[0.7627]], device='cuda:0')
图文结合1 vs 图文结合2: tensor([[0.9058]], device='cuda:0')
=== 嵌入向量信息 ===
多模态向量维度: torch.Size([1, 768])
图像向量维度: torch.Size([1, 768])
多模态向量示例 (前10个元素): tensor([ 0.0360, -0.0032, -0.0377, 0.0240, 0.0140, 0.0340, 0.0148, 0.0292, 0.0060, -0.0145], device='cuda:0')
图像向量示例 (前10个元素): tensor([ 0.0407, -0.0606, -0.0037, 0.0073, 0.0305, 0.0318, 0.0132, 0.0442, -0.0380, -0.0270], device='cuda:0')
代码总结
- 通过相似度计算结果可以看出,两个图文结合的嵌入相似度是最高的,对图文检索很有价值:即使图片不同,相同文本也能将它们关联起来;
- 多模态和图像的向量维度都是
768,是BERT系列模型的标准维度; - 两个向量维度相同,说明模型使用了统一的向量空间;
- 数值精度高(小数点后4位),保持了丰富的语义信息
练习
- 将图像2的文本改为
蓝鲸,输出结果如下
纯图像 vs 纯图像: tensor([[0.8318]], device='cuda:0')
图文结合1 vs 纯图像: tensor([[0.8291]], device='cuda:0')
图文结合1 vs 纯文本: tensor([[0.7627]], device='cuda:0')
图文结合1 vs 图文结合2: tensor([[0.7631]], device='cuda:0')
总结
- 语义敏感性:模型对文本变化高度敏感
- 融合有效性:图文信息真正融合而非简单拼接
- 应用可控性:通过调节文本描述可以精确控制检索结果
- 实用价值:在实际RAG系统中具备精细调节能力