学习文档地址:第三章 第三节 向量数据库
什么是向量数据库
在上一章,我们了解了向量嵌入的基础概念,即将多模态的图像、文本等进行向量化,成为多维向量数据。而向量数据库,可以提供对这些向量数据的存储和查询功能。毕竟在 RAG 中,我们并不能像 MySQL 那样通过where id = 3去查询数据,只能通过相似性去查找。
- 高效的相似性搜索:这是向量数据库最重要的功能。它利用专门的索引技术(如 HNSW, IVF),能够在数十亿级别的向量中实现毫秒级的近似最近邻(ANN)查询,快速找到与给定查询最相似的数据。
- 高维数据存储与管理:专门为存储高维向量(通常维度成百上千)而优化,支持对向量数据进行增、删、改、查等基本操作。
- 丰富的查询能力:除了基本的相似性搜索,还支持按标量字段过滤查询(例如,在搜索相似图片的同时,指定
年份 > 2023)、范围查询和聚类分析等,满足复杂业务需求。 - 可扩展与高可用:现代向量数据库通常采用分布式架构,具备良好的水平扩展能力和容错性,能够通过增加节点来应对数据量的增长,并确保服务的稳定可靠。
- 数据与模型生态集成:与主流的 AI 框架(如 LangChain, LlamaIndex)和机器学习工作流无缝集成,简化了从模型训练到向量检索的应用开发流程。
工作原理
向量数据库通常采用四层架构,通过以下技术手段实现高效相似性搜索:
- 存储层:存储向量数据和元数据,优化存储效率,支持分布式存储
- 索引层:维护索引算法(HNSW、LSH、PQ等),创建和优化索引,支持索引调整
- 查询层:处理查询请求,支持混合查询,实现查询优化
- 服务层:管理客户端连接,提供监控和日志,实现安全管理
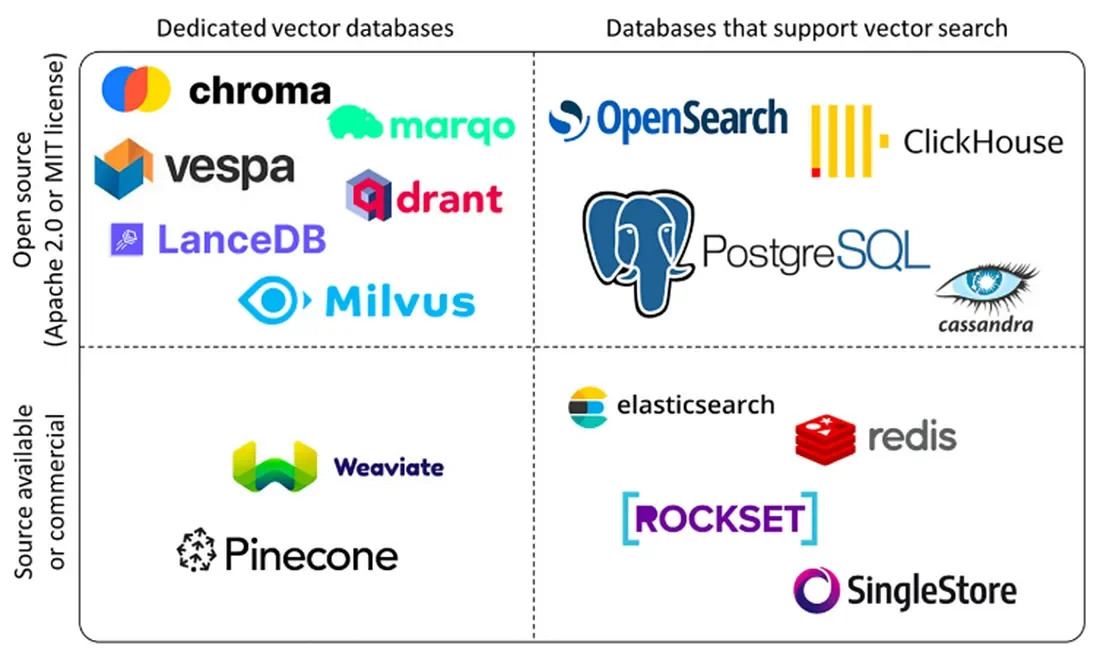
主流向量数据库
| 数据库 (Database) | 类型 | 核心特点与优势 | 主要应用场景 |
|---|---|---|---|
| Milvus / Zilliz | 开源分布式系统 / 云服务 | 功能最全面、生态最成熟的开源标准。- 为大规模设计:纯粹的分布式架构,支持水平扩展,能处理百亿甚至千亿级别的向量。- 高度可配置:支持多种索引类型(如HNSW, IVFFlat)和距离度量,可根据场景调优。- 企业级特性:支持多租户、分区、TTL等高级功能。- Zilliz Cloud提供全托管服务,由原厂打造。 | 大规模、生产级的AI应用。需要处理海量向量、对性能和可扩展性有极高要求的企业级搜索引擎、推荐系统、AI安全等。 |
| Pinecone | 商业闭源云服务 (SaaS) | 简单易用、性能卓越的全托管服务。- 开箱即用:完全的SaaS模式,无需任何运维,开发者体验极佳。- 性能稳定:以低延迟和高召回率著称,针对实时应用做了深度优化。- 无服务器架构 (Serverless):根据使用量自动伸缩,无需关心底层资源。- 提供了命名空间(Namespace)等方便多租户管理的工具。 | 快速开发和迭代的AI原生应用。希望将精力完全集中在应用逻辑上,不想处理任何数据库运维的初创公司和企业团队。 |
| Weaviate | 开源 / 云服务 | 内置数据处理与GraphQL API。- 开箱即用的模块化:内置了与OpenAI, Cohere等模型的集成模块,可以在数据库内部完成数据的向量化。- GraphQL API:提供强大的GraphQL查询接口,便于进行复杂的数据关联查询。- 混合搜索:原生支持关键词搜索和向量搜索的混合,非常实用。 | 需要将向量搜索与结构化数据过滤紧密结合的场景。希望在数据库层面解决更多数据处理问题的应用。 |
| Qdrant | 开源 / 云服务 | 性能与内存安全。- Rust语言编写:提供了内存安全保证和出色的性能。- 高级过滤与量化:支持丰富的元数据过滤条件,并且提供了先进的标量量化和二值量化技术,能在保持高精度的同时,显著降低内存消耗和成本。- 分片与推荐系统:支持分片和集合推荐等高级功能。 | 对性能、资源效率和数据过滤能力有苛刻要求的场景。希望在有限的硬件资源下实现高性能检索的应用。 |
| ChromaDB | 开源 / 嵌入式优先 | 为AI开发者打造的“开发者友好”数据库。- 嵌入式优先:可以作为Python库直接在应用中运行,无需部署单独的服务,极大地简化了开发和原型验证。- API简单直观:专为AI工作流(特别是RAG)设计,API非常易于上手。- 分析功能:提供了一些内置的工具来分析和可视化你的嵌入数据。 | 本地开发、快速原型验证、中小型RAG应用。作为Jupyter Notebook/Streamlit等应用的一部分,进行数据科学实验和构建Demo。 |
| PGVector | PostgreSQL 扩展 | 在现有关系型数据库中增加向量能力。- 生态成熟:可以完全利用PostgreSQL强大的生态系统,如事务、备份、权限管理、丰富的SQL功能等。- 数据统一:无需维护一个独立的数据库,可以将向量数据与业务的结构化数据存储在一起,方便进行联合查询。- 运维简单:对于已经在使用PostgreSQL的团队,学习和维护成本极低。 | 已经在使用PostgreSQL,并希望快速、低成本地为现有应用增加向量搜索功能的场景。数据混合查询(例如,查找“过去30天内,由A部门创建的,内容与‘AI安全’相关的文档”)需求强烈的应用。 |
如何选择
以 FAISS 为例
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_core.documents import Document
# 1. 示例文本和嵌入模型
texts = [
"张三是法外狂徒",
"FAISS是一个用于高效相似性搜索和密集向量聚类的库。",
"LangChain是一个用于开发由语言模型驱动的应用程序的框架。"
]
docs = [Document(page_content=t) for t in texts]
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 2. 创建向量存储并保存到本地
vectorstore = FAISS.from_documents(docs, embeddings)
local_faiss_path = "./faiss_index_store"
vectorstore.save_local(local_faiss_path)
print(f"FAISS index has been saved to {local_faiss_path}")
# 3. 加载索引并执行查询
# 加载时需指定相同的嵌入模型,并允许反序列化
loaded_vectorstore = FAISS.load_local(
local_faiss_path,
embeddings,
allow_dangerous_deserialization=True
)
# 相似性搜索
query = "FAISS是做什么的?"
results = loaded_vectorstore.similarity_search(query, k=1)
print(f"\n查询: '{query}'")
print("相似度最高的文档:")
for doc in results:
print(f"- {doc.page_content}")
练习
- LlamaIndex默认会将数据存储为透明可读的JSON格式,运行03_llamaindex_vector.py文件,查看保存的json文件内容。
- default__vector_store.json - 核心向量存储
- 存储文本节点的 512 维向量嵌入
- 包含节点ID到向量的映射关系
- 实际保存中文文本的数值化表示
- docstore.json - 文档存储
- 保存原始中文文本内容
- 维护文档与节点的层级关系
- 包含"张三是法外狂徒"等示例文本
- index_store.json - 索引元数据
- 存储索引配置信息
- 记录节点存储位置映射
- 提供索引重构的元信息
- image__vector_store.json - 图像向量存储(当前为空)
- 预留用于多模态检索
- 可存储图像+文本的联合嵌入
- graph_store.json - 图关系存储(当前为空)
- 预留用于知识图谱扩展
- 可存储文档间的实体关系
- 新建一个代码文件实现对LlamaIndex存储数据的加载和相似性搜索。
from llama_index.core import (
Document,
Settings,
load_index_from_storage,
StorageContext,
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 1. 配置全局嵌入模型
Settings.embed_model = HuggingFaceEmbedding("BAAI/bge-small-zh-v1.5")
# 2. 创建示例文档
texts = [
"张三是法外狂徒",
"LlamaIndex是一个用于构建和查询私有或领域特定数据的框架。",
"它提供了数据连接、索引和查询接口等工具。",
]
docs = [Document(text=t) for t in texts]
# 3. 创建索引并持久化到本地
index = VectorStoreIndex.from_documents(docs)
persist_path = "./llamaindex_index_store"
index.storage_context.persist(persist_dir=persist_path)
print(f"LlamaIndex 索引已保存至: {persist_path}")
# 4. 加载索引
loaded_index = StorageContext.from_defaults(persist_dir=persist_path)
vector_idnex = load_index_from_storage(loaded_index)
# 5. 构建查询
# 设置LlamaIndex的配置,使用本地Ollama大模型
from llama_index.llms.ollama import Ollama
Settings.llm = Ollama(
model="gemma3-4b:Q4_K_M", base_url="http://127.0.0.1:11434", request_timeout=150
)
query = "LlamaIndex是做什么的?"
query_engine = vector_idnex.as_query_engine()
response = query_engine.query(query)
print(f"\n查询: '{query}'")
print(f"回答: {response}")
LlamaIndex 索引已保存至: ./llamaindex_index_store
Loading llama_index.core.storage.kvstore.simple_kvstore from ./llamaindex_index_store\docstore.json.
Loading llama_index.core.storage.kvstore.simple_kvstore from ./llamaindex_index_store\index_store.json.
查询: 'LlamaIndex是做什么的?'
回答: LlamaIndex用于构建和查询私有或领域特定数据。
Milvus数据库
Milvus 是一个开源的、专为大规模向量相似性搜索和分析而设计的向量数据库,专为生产环境而设计。
版本对比
| 版本 | 部署模式 | 架构 | 核心优势 | 核心劣势 | 最佳适用场景 |
|---|---|---|---|---|---|
| Milvus Standalone | 自托管 | 单机单进程 | 极其简单,快速启动 | 无高可用,扩展性有限 | 学习、开发、原型验证(MVP)、小型应用 |
| Milvus Cluster | 自托管 | 分布式微服务 | 高性能,高可用,可处理海量数据 | 部署运维复杂,资源成本高 | 大规模、数据私有化的生产环境 |
| Zilliz Cloud | 全托管 | 分布式云原生 | 完全免运维,Serverless,快速上线 | 依赖云服务,长期成本可能更高 | 追求开发速度、希望外包运维的各类生产应用 |
基本概念
| Milvus 概念 | 传统数据库 (如 MySQL) 类比 | 解释 |
|---|---|---|
| Collection (集合) | Table (表) | 一个 Collection 就是一张数据表,是数据管理的顶层容器。例如,你可以创建一个名为 rag_documents 的 Collection 来存储所有用于RAG的文档块。 |
| Partition (分区) | Partition (分区) | 这是一个可选的物理存储概念。你可以将一个 Collection 划分为多个 Partition,查询时可以指定只在某个分区内搜索,这能有效隔离数据并提升查询性能。例如,可以按书籍名称创建分区。 |
| Schema (模式) | Table Definition / DDL (表结构定义) | Schema 定义了一个 Collection 中包含哪些“列”(在Milvus中称为 Field),以及每一列的数据类型和约束。创建 Collection 时必须先定义好 Schema。 |
| Entity (实体) | Row (行) | 一个 Entity 就是表中的一行数据。它包含了 Schema 中定义的所有 Field 的具体值。在RAG场景中,一个 Entity 通常就代表一个文本块(Chunk)。 |
| Field (字段) | Column (列) | Field 就是表中的一列。一个 Schema 由多个 Field 组成。例如,chunk_id, chunk_text, chunk_vector 都可以是 Field。 |
| Alias(别名) | 类似于View,但有本质区别 | Alias 是一个指向某个特定 Collection 的虚拟指针或昵称。能在无需修改代码和重启服务器的基础上,无缝升级数据。 |
Collection
在 Milvus 上,可以创建多个 Collections 来管理数据,并将数据作为实体插入到 Collections 中。Collections 和实体类似于关系数据库中的表和记录。
一个 Collection Schema 有一个主键、最多四个向量字段和几个标量字段。下图说明了如何将文章映射到模式字段列表。
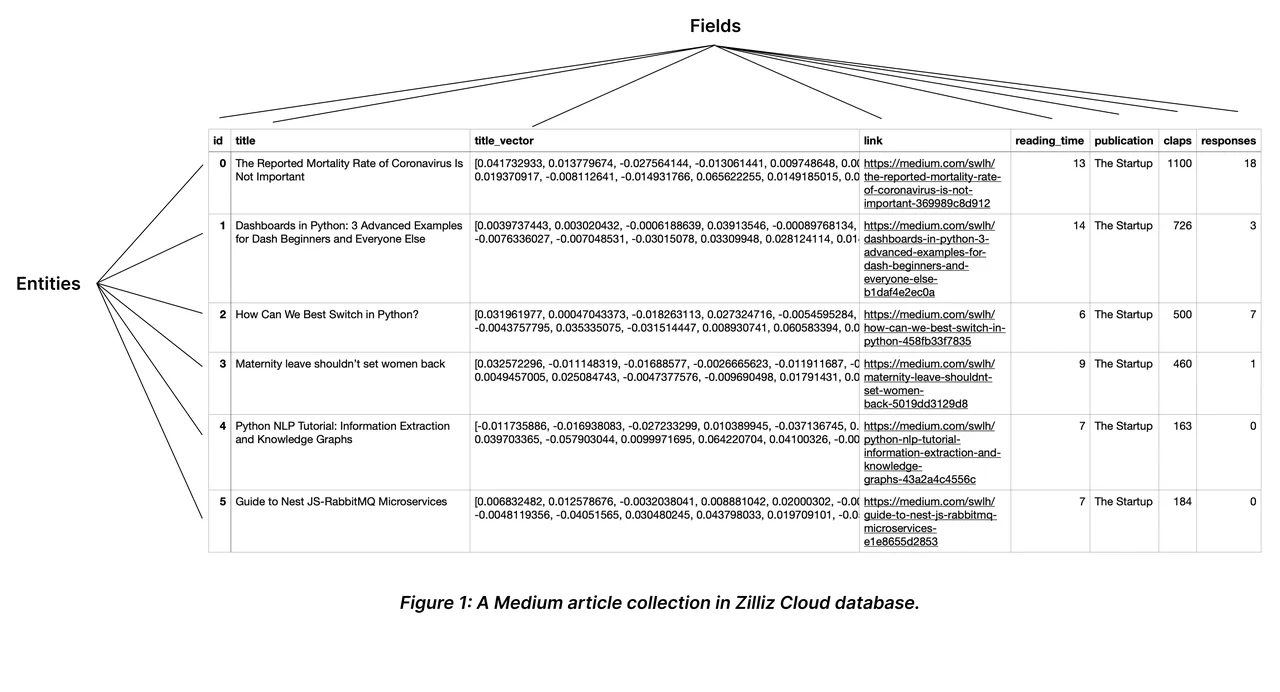
Schema
Schema 定义了 Collections 的数据结构。
一个 Collection Schema 有一个主键、最多四个向量字段和几个标量字段。下图说明了如何将文章映射到模式字段列表。
Article是主键字段,每篇文章只有唯一且不重复的ID;ImageEmbeddingSummary EmbeddingSummarySpareEmbedding是向量字段;- 其他信息属于标量字段,用于更好的检索;
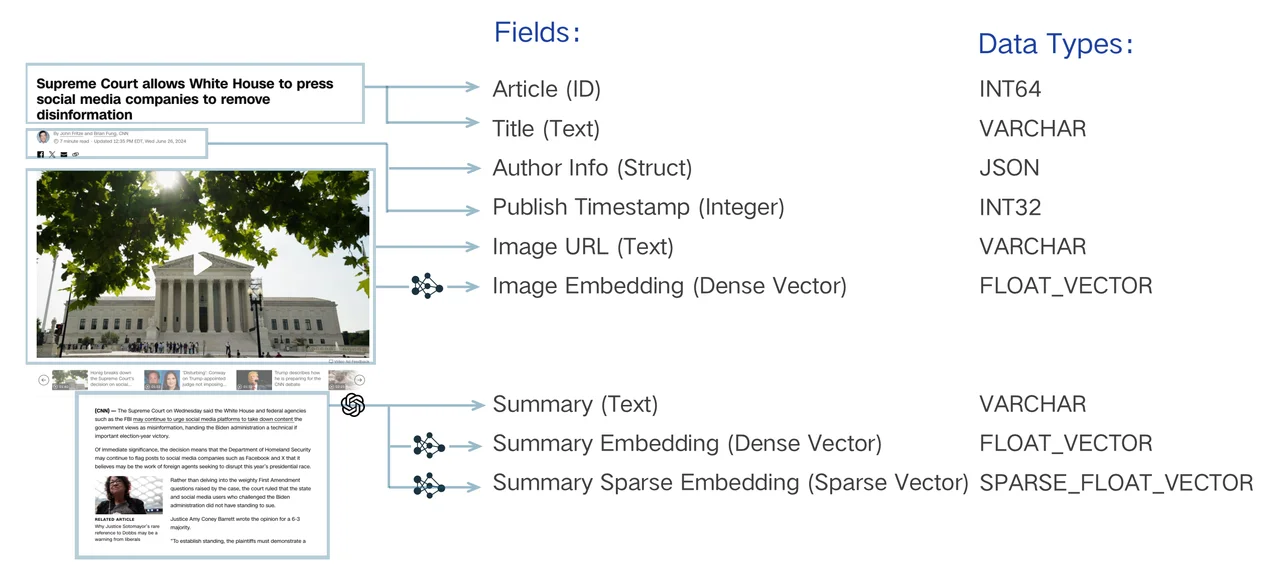
主键字段
在 Collections 中,每个实体的主键都应该是全局唯一的。添加主字段时,需要显式地将其数据类型设置为VARCHAR或INT64。将其数据类型设置为INT64表示主键应为整数,类似于12345 ;将其数据类型设置为VARCHAR表示主键应为字符串,类似于my_entity_1234 。
你也可以启用AutoID,让 Milvus 自动为进入的实体分配主键。在集合中启用AutoID后,插入实体时不要包含主键。
Collections 中的主字段没有默认值,也不能为空。
Partition
每个 Collection 在创建时都会有一个名为 _default 的默认分区。我们可以根据业务需求创建更多的分区,将数据按特定规则(如类别、日期等)存入不同分区。
一个 Collections 最多可以有 1024 个分区。
Alias
在 Milvus 中,别名是一个 Collection 的二级可变名称。使用别名提供了一个抽象层,使您可以在不修改应用程序代码的情况下动态切换 Collections。这对于生产环境中的无缝数据更新、A/B 测试和其他操作符特别有用。
别名的关键属性:
- 一个 Collection 可以有多个别名。
- 一个别名一次只能指向一个 Collections。
- 处理请求时,Milvus 会首先检查是否存在提供名称的 Collection。如果不存在,它就会检查该名称是否是某个 Collection 的别名。
索引
MySQL 索引是“精确找行”,Milvus 索引是“模糊找相似”。
检索
类似于传统数据库的查询,但是有些本质区别。传统数据库的查询是基于精确匹配,而检索是基于语义的相似性。
基础向量检索(ANN Search)
近似最近邻 (Approximate Nearest Neighbor, ANN) 检索
ANN 检索利用预先构建好的索引,能够极速地从海量数据中找到与查询向量最相似的 Top-K 个结果;
Milvus多模态实践
示例代码 all-in-rag/code/C3/04_multi_milvus.py
输出结果
我在图片库中又找了几张网图加进去,看整体效果
检索结果:
Top 1: ID=460393204701700350, 距离=0.9466, 路径='../../data/C3\dragon\query.png'
Top 2: ID=460393204701700344, 距离=0.7443, 路径='../../data/C3\dragon\dragon02.png'
Top 3: ID=460393204701700348, 距离=0.6851, 路径='../../data/C3\dragon\dragon06.png'
Top 4: ID=460393204701700341, 距离=0.6772, 路径='../../data/C3\dragon\dragon001.png'
Top 5: ID=460393204701700343, 距离=0.6760, 路径='../../data/C3\dragon\dragon003.png'
Top 6: ID=460393204701700342, 距离=0.6459, 路径='../../data/C3\dragon\dragon002.png'
Top 7: ID=460393204701700345, 距离=0.6049, 路径='../../data/C3\dragon\dragon03.png'
Top 8: ID=460393204701700347, 距离=0.5360, 路径='../../data/C3\dragon\dragon05.png'
第一张图就是query.png,但是从检索结果可以看到,它的距离也不是1,而是0.9466,这是因为,索引时的图片和检索时的图片处理有差异;
从代码可以看出,编码查询的时候除了输入图像,我们还输入了text查询文本,这样就会使得同一图片的检索距离并不为1。如果去掉这个一条龙的描述,则距离结果就是1了;
# 编码查询
def encode_query(self, image_path: str, text: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=image_path, text=text)
return query_emb.tolist()[0]
# 编码图像
def encode_image(self, image_path: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=image_path)
return query_emb.tolist()[0]
query_text = "一条龙"
# 查询编码使用的是图片+文本
query_vector = encoder.encode_query(image_path=query_image_path, text=query_text)
# 如果直接采用图片,不使用文本,则会显示距离为1
# query_vector = encoder.encode_image(image_path=query_image_path)
- 查询编码时不加入文字的结果
检索结果:
Top 1: ID=460393204701700360, 距离=1.0000, 路径='../../data/C3\dragon\query.png'
Top 2: ID=460393204701700354, 距离=0.7908, 路径='../../data/C3\dragon\dragon02.png'
Top 3: ID=460393204701700351, 距离=0.7321, 路径='../../data/C3\dragon\dragon001.png'
Top 4: ID=460393204701700358, 距离=0.6975, 路径='../../data/C3\dragon\dragon06.png'
Top 5: ID=460393204701700353, 距离=0.6867, 路径='../../data/C3\dragon\dragon003.png'
Top 6: ID=460393204701700355, 距离=0.6592, 路径='../../data/C3\dragon\dragon03.png'
Top 7: ID=460393204701700352, 距离=0.6551, 路径='../../data/C3\dragon\dragon002.png'
Top 8: ID=460393204701700357, 距离=0.5703, 路径='../../data/C3\dragon\dragon05.png'
