稀疏向量VS密集向量
稀疏向量
稀疏向量,也常被称为词法向量,是基于词频统计的传统信息检索方法的数学表示。采用词袋模型,将一段文本全部的词汇分开,然后将每一个词作为一个维度。一般来说,绝大多数元素为0。
这类向量的典型代表是 TF-IDF 和 BM25,其中,BM25 是目前最成功、应用最广泛的稀疏向量计分算法之一。
优点:
- 简单易懂,易于实现: 词袋模型概念简单,容易理解和实现。这使得它成为文本处理任务的理想起点。
- 计算效率高: 由于其简单性,词袋模型的计算效率非常高。对于大规模文本数据集,它能够快速地进行处理和分析。
- 对文本分类任务有一定效果: 在一些简单的文本分类任务中,词袋模型能够取得不错的效果。例如,垃圾邮件检测、情感分析等。
- 可以与其他模型结合: 词袋模型可以作为特征工程的一部分,与其他更复杂的模型(如神经网络)结合使用,以提高性能。
缺点:
- 忽略词语顺序和语法: 这是词袋模型最大的缺点。它无法捕捉词语之间的语义关系和上下文信息,导致对文本的理解不够深入。例如,“苹果”水果和“苹果”公司在词袋模型中会被认为是相同的,尽管它们的含义完全不同。
- 无法处理一词多义和多词一义: 词袋模型将每个词语视为独立的个体,无法区分同一个词语的不同含义(一词多义),也无法处理多个词语表达相同含义的情况(多词一义)。
- 维度灾难: 当词汇量很大时,词袋模型的特征向量会变得非常稀疏,导致维度灾难。这会增加计算复杂度和存储空间的需求,并可能降低模型的泛化能力。
- 对新词和罕见词的处理不佳: 词袋模型无法很好地处理训练集中未出现的新词,以及在训练集中出现频率很低的罕见词。
举个栗子
一个8维的稀疏向量,[0, 0, 0, 5, 0, 0, 0, 9]
我们可以写成:
// {索引: 值}
{
"3": 5,
"7": 9
}
也可以写成
(8, [3, 7], [5, 9])
密集向量
密集向量,也常被称为语义向量,是通过深度学习模型学习到的数据(如文本、图像)的低维、稠密的浮点数表示。
它的典型代表包括 Word2Vec、GloVe、以及所有基于 Transformer 的模型(如 BERT、GPT)生成的嵌入(Embeddings)。
优点:
- 语义捕捉:密集向量能够有效处理同义词,因为它们会被映射到相似的向量。这使得模型能够理解词语之间的语义关系。
- 上下文敏感:对于多义词,密集向量可以根据上下文的不同而有所变化,从而捕捉到不同的含义。这种特性在处理复杂文本时非常有用。
- 高效的相似度计算:密集向量之间的距离计算(如欧氏距离和余弦相似度)可以快速进行,适合大规模数据集的处理。
- 良好的泛化能力:由于密集向量能够捕捉到深层的语义信息,它们在许多任务中表现出色,尤其是在文本分类和推荐系统中。
缺点:
- 计算成本高:尽管密集向量在相似度计算上高效,但在训练过程中,尤其是处理大规模数据时,计算成本仍然较高。
- 对数据质量敏感:密集向量的效果依赖于训练数据的质量。如果训练数据不够丰富或存在偏差,生成的向量可能无法准确反映语义。
- 维度灾难:在某些情况下,维度过高可能导致模型的复杂性增加,进而影响训练和推理的效率。
- 生态系统不成熟:相较于传统的稀疏向量和关系数据库,密集向量的生态系统仍在发展中,可能缺乏一些成熟的工具和框架。
混合检索
通过两种方式相结合,应对复杂多变的搜索需求。
倒数排序融合
倒数排序融合 (Reciprocal Rank Fusion, RRF),其思想是:一个文档在不同检索系统中的排名越靠前,它的最终得分就越高。
其中:
- 是待评分的文档。
- 是检索系统的数量(这里是2,即稀疏和密集)。
- 是文档 在第 个检索系统中的排名。
- 是一个常数(通常设为60),用于降低排名靠后文档的权重,避免它们对结果产生过大影响。
加权线性组合
其中:
- 是权重参数,可以通过这个参数来控制最终两个搜索的贡献比例。
- 是密集向量检索得分。
- 是稀疏向量检索得分。
- 两个检索分数需要先进行归一化,统一到同一区间(一般是)。
代码实践
定义Collection
在上一章,我们实现了向量空间多模态的检索,这部分差不多,但是这次我们的输入会有点不一样。上一章只输入了图片,没有其他元数据了,这次增加了很多描述元数据。如下所示:
[
{
"img_id": "dragon02",
"path": "../../data/C3/dragon/dragon02.png",
"title": "悬崖上的白龙",
"description": "一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。",
"category": "western_dragon",
"location": "悬崖海岸",
"environment": "天空"
},
...
]
import json
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
import numpy as np
from pymilvus import connections, MilvusClient, FieldSchema, CollectionSchema, DataType, Collection, AnnSearchRequest, RRFRanker
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
# 1. 初始化设置
COLLECTION_NAME = "dragon_hybrid_demo"
MILVUS_URI = "http://192.168.3.9:19530" # 服务器模式
DATA_PATH = "../../data/C4/metadata/dragon.json" # 相对路径
BATCH_SIZE = 50
# 2. 连接 Milvus 并初始化嵌入模型
print(f"--> 正在连接到 Milvus: {MILVUS_URI}")
connections.connect(uri=MILVUS_URI)
print("--> 正在初始化 BGE-M3 嵌入模型...")
# 这里改用GPU
ef = BGEM3EmbeddingFunction(use_fp16=False, device="cuda")
print(f"--> 嵌入模型初始化完成。密集向量维度: {ef.dim['dense']}")
# 3. 创建 Collection
milvus_client = MilvusClient(uri=MILVUS_URI)
if milvus_client.has_collection(COLLECTION_NAME):
print(f"--> 正在删除已存在的 Collection '{COLLECTION_NAME}'...")
milvus_client.drop_collection(COLLECTION_NAME)
# 定义字段,包括主键、图片ID、路径、标题、描述等
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="img_id", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="path", dtype=DataType.VARCHAR, max_length=256),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=256),
FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=4096),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=64),
FieldSchema(name="location", dtype=DataType.VARCHAR, max_length=128),
FieldSchema(name="environment", dtype=DataType.VARCHAR, max_length=64),
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=ef.dim["dense"])
]
# 如果集合不存在,则创建它及索引
if not milvus_client.has_collection(COLLECTION_NAME):
print(f"--> 正在创建 Collection '{COLLECTION_NAME}'...")
schema = CollectionSchema(fields, description="关于龙的混合检索示例")
# 创建集合
collection = Collection(name=COLLECTION_NAME, schema=schema, consistency_level="Strong")
print("--> Collection 创建成功。")
# 4. 创建索引
print("--> 正在为新集合创建索引...")
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
collection.create_index("sparse_vector", sparse_index)
print("稀疏向量索引创建成功。")
dense_index = {"index_type": "AUTOINDEX", "metric_type": "IP"}
collection.create_index("dense_vector", dense_index)
print("密集向量索引创建成功。")
collection = Collection(COLLECTION_NAME)
加载数据并插入
docs, metadata = [], []
# 把json文件中的所有k-v都写入
for item in dataset:
parts = [
item.get('title', ''),
item.get('description', ''),
item.get('location', ''),
item.get('environment', ''),
# *item.get('combat_details', {}).get('combat_style', []),
# *item.get('combat_details', {}).get('abilities_used', []),
# item.get('scene_info', {}).get('time_of_day', '')
]
docs.append(' '.join(filter(None, parts)))
metadata.append(item)
print(f"--> 数据加载完成,共 {len(docs)} 条。")
print("--> 正在生成向量嵌入...")
embeddings = ef(docs)
print("--> 向量生成完成。")
print("--> 正在分批插入数据...")
# 为每个字段准备批量数据
img_ids = [doc["img_id"] for doc in metadata]
paths = [doc["path"] for doc in metadata]
titles = [doc["title"] for doc in metadata]
descriptions = [doc["description"] for doc in metadata]
categories = [doc["category"] for doc in metadata]
locations = [doc["location"] for doc in metadata]
environments = [doc["environment"] for doc in metadata]
# 获取向量
sparse_vectors = embeddings["sparse"] # 稀疏向量
dense_vectors = embeddings["dense"] # 密集向量
# 插入数据
collection.insert([
img_ids,
paths,
titles,
descriptions,
categories,
locations,
environments,
sparse_vectors,
dense_vectors
])
# 刷新集合
collection.flush()
执行搜索
# 搜索语句
search_query = "悬崖上的巨龙"
# 搜索筛选,这里限定了`category`只在这三个里面
search_filter = 'category in ["western_dragon", "chinese_dragon", "movie_character"]'
top_k = 5
# 构建查询语句的向量
query_embeddings = ef([search_query])
# 拿到查询语句的密集向量和稀疏向量
dense_vec = query_embeddings["dense"][0]
sparse_vec = query_embeddings["sparse"]._getrow(0)
# 单独的密集搜索
dense_results = collection.search(
[dense_vec],
anns_field="dense_vector",
param=search_params,
limit=top_k,
expr=search_filter,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]
# 上面这里取第一个,因为我们查询只输入了一个查询向量[dense_vec],所以只会有一个result
# 单独稀疏向量搜索
sparse_results = collection.search(
[sparse_vec],
anns_field="sparse_vector",
param=search_params,
limit=top_k,
expr=search_filter,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]
# 创建 RRF 融合器
rerank = RRFRanker(k=60)
# 创建搜索请求
dense_req = AnnSearchRequest([dense_vec], "dense_vector", search_params, limit=top_k)
sparse_req = AnnSearchRequest([sparse_vec], "sparse_vector", search_params, limit=top_k)
# 执行混合搜索
results = collection.hybrid_search(
[sparse_req, dense_req],
rerank=rerank,
limit=top_k,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]
输出结果
--- [单独] 密集向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.7219)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.5131)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 驯龙高手:无牙仔 (Score: 0.5119)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...
--- [单独] 稀疏向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.2319)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.0923)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 驯龙高手:无牙仔 (Score: 0.0691)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...
--- [混合] 稀疏+密集向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.0328)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.0320)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 霸王龙的怒吼 (Score: 0.0318)
路径: ../../data/C3/dragon/dragon03.png
描述: 史前时代的霸王龙张开血盆大口,发出震天的怒吼。在它身后,几只翼龙在阴沉的天空中盘旋,展现了白垩纪的原始力量。...
4. 奔跑的奶龙 (Score: 0.0313)
路径: ../../data/C3/dragon/dragon04.png
描述: 一只Q版的黄色小恐龙,有着大大的绿色眼睛和友善的微笑。是一部动画中的角色,非常可爱。...
5. 驯龙高手:无牙仔 (Score: 0.0310)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...
练习
分析代码为什么在密集向量检索和稀疏向量检索中,排名第三的驯龙高手在混合检索中反而排在了第五?
- 分析代码可以看出,在进行单独搜索时,
collection.search()里面都有一个expr参数,这里输入了search_filter,是用来筛选元数据的; - 但是在混合搜索时,
AnnSearchRequest里却没有增加这限制,会导致输出结果并不相同,以至于最后的结果有差异; - 如果将代码进行修改,增加filter,则最终结果会与单独搜索结果相同;
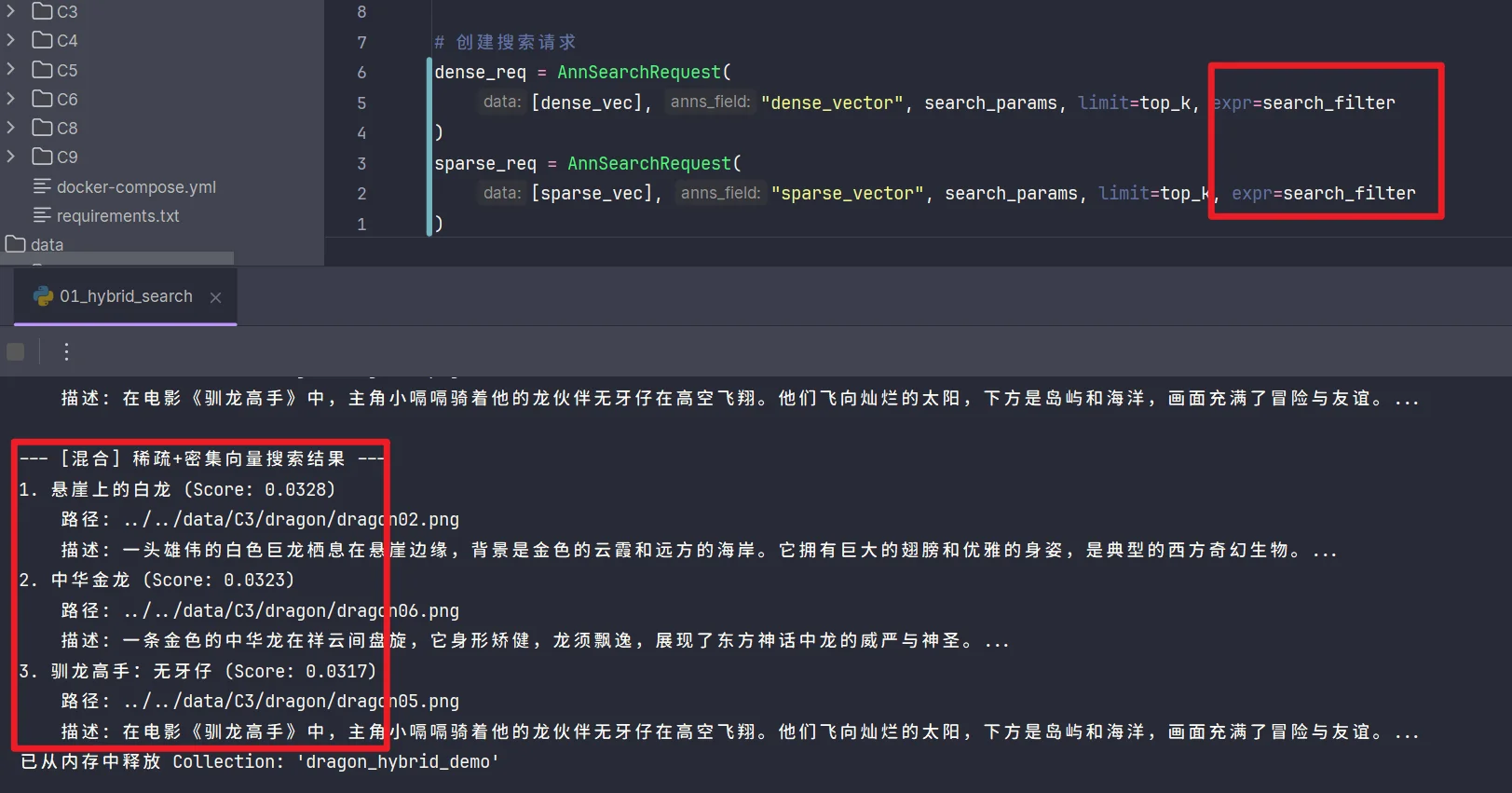
dense_req = AnnSearchRequest([dense_vec], "dense_vector", search_params, limit=top_k, expr=search_filter)
sparse_req = AnnSearchRequest([sparse_vec], "sparse_vector", search_params, limit=top_k, expr=search_filter)
- 当然,也可以将单独搜索的filter先去掉,然后我们在看结果如下,然后,通过RFF公式计算每个结果的分数;
- 将所有结果进行排序并计算RRF,可以看到,因为稀疏向量搜索时,奶龙排名第二,导致最后混合搜索时,其综合排名上升到了第三。通过RRF手动计算的得分,也与代码输出一致;
| 结果 | dense_rank | sparse_rank | RRF | 混合结果排名 |
|---|---|---|---|---|
| 白龙 | 1 | 1 | 0.032787 | 1 |
| 中华金龙 | 2 | 3 | 0.032002 | 2 |
| 驯龙高手 | 3 | 5 | 0.031258 | 4 |
| 霸王龙 | 4 | 4 | 0.031250 | 5 |
| 奶龙 | 5 | 2 | 0.031514 | 3 |
| 金丝猴 | 6 | 6 | 0.030303 | 6 |
--- [混合] 稀疏+密集向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.0328)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.0320)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 奔跑的奶龙 (Score: 0.0315)
路径: ../../data/C3/dragon/dragon04.png
描述: 一只Q版的黄色小恐龙,有着大大的绿色眼睛和友善的微笑。是一部动画中的角色,非常可爱。...
4. 驯龙高手:无牙仔 (Score: 0.0313)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...
5. 霸王龙的怒吼 (Score: 0.0312)
路径: ../../data/C3/dragon/dragon03.png
描述: 史前时代的霸王龙张开血盆大口,发出震天的怒吼。在它身后,几只翼龙在阴沉的天空中盘旋,展现了白垩纪的原始力量。...
6. 金丝猴 (Score: 0.0303)
路径: ../../data/C3/dragon/other01.png
描述: 一只珍稀的金丝猴坐靠在树干上,悠闲地吃着食物。它拥有金色的长毛和蓝色的脸庞,是中国的特有物种。...
基于上一节的多模态检索代码
练习的题目是说将多模态用混合检索,上一节的多模态是将文本+图片向量化,而上文并没有用多模态,只是将文本进行了不同的向量化。
一开始的思路,是将图片分别进行密集向量化和稀疏向量化,后来发现图片不能进行稀疏向量化,根本原因在于图像数据是连续的、空间相关的,而文本数据是离散的、符号化的。
然后就沿用本节思路,将一些文本,例如title description 等进行稀疏向量化,然后进行混合检索。
具体输出结果如下:
import os
import json
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
from pymilvus import (
MilvusClient,
FieldSchema,
CollectionSchema,
DataType,
RRFRanker,
AnnSearchRequest,
)
import numpy as np
# 1. 初始化设置
MODEL_NAME = "BAAI/bge-base-en-v1.5"
MODEL_PATH = r"Visualized_base_en_v1.5.pth"
DATA_DIR = "../../data/C3"
COLLECTION_NAME = "multimodal_demo"
MILVUS_URI = "http://192.168.3.9:19530"
DATA_PATH = "../../data/C4/metadata/dragon.json"
ef = BGEM3EmbeddingFunction(use_fp16=False, device="cuda")
# 2. 定义工具 (编码器和可视化函数)
class Encoder:
"""编码器类,用于将图像和文本编码为向量。"""
def __init__(self, model_name: str, model_path: str):
self.model = Visualized_BGE(model_name_bge=model_name, model_weight=model_path)
self.model.eval()
def encode_query(self, img_path: str, text: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=img_path, text=text)
return query_emb.tolist()[0]
def encode_image(self, img_path: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=img_path)
return query_emb.tolist()[0]
# 3. 初始化客户端
print("--> 正在初始化编码器和Milvus客户端...")
encoder = Encoder(MODEL_NAME, MODEL_PATH)
milvus_client = MilvusClient(uri=MILVUS_URI)
# 4. 创建 Milvus Collection
print(f"\n--> 正在创建 Collection '{COLLECTION_NAME}'")
if milvus_client.has_collection(COLLECTION_NAME):
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除已存在的 Collection: '{COLLECTION_NAME}'")
# 加载数据
text_data, meta_data = [], []
if not os.path.exists(DATA_PATH):
raise FileNotFoundError(f"数据文件未找到: {DATA_PATH}")
with open(DATA_PATH, "r", encoding="utf-8") as f:
dataset = json.load(f)
for item in dataset:
parts = [
item.get("title", ""),
item.get("description", ""),
]
text_data.append(" ".join(filter(None, parts)))
meta_data.append(item)
image_list = [item.get("path") for item in meta_data]
if not image_list:
raise FileNotFoundError(f"在 {DATA_DIR}/dragon/ 中未找到任何 .png 图像。")
dim = len(encoder.encode_image(image_list[0]))
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=4096),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=dim),
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=dim),
]
# 创建集合 Schema
schema = CollectionSchema(fields, description="多模态图文检索")
# print("Schema 结构:")
# print(schema)
# 创建集合
milvus_client.create_collection(collection_name=COLLECTION_NAME, schema=schema)
print(f"成功创建 Collection: '{COLLECTION_NAME}'")
# print("Collection 结构:")
# print(milvus_client.describe_collection(collection_name=COLLECTION_NAME))
# 5. 准备并插入数据
# 文本向量
text_vector = ef(text_data)
# 为每个字段准备批量数据
titles = [doc["title"] for doc in meta_data]
descriptions = [doc["description"] for doc in meta_data]
vector = [encoder.encode_image(doc["path"]) for doc in meta_data]
sparse_vectors = text_vector["sparse"]
dense_vectors = vector
sparse_vec_list = []
for i in range(sparse_vectors.shape[0]):
row = sparse_vectors._getrow(i)
sparse_dict = {int(col): float(row.data[j]) for j, col in enumerate(row.indices)}
sparse_vec_list.append(sparse_dict)
# 插入数据
print(f"\n--> 正在向 '{COLLECTION_NAME}' 插入数据")
data_to_insert = []
for i, title in enumerate(titles):
data_to_insert.append(
{
"title": title,
"vector": vector[i],
"description": descriptions[i],
"sparse_vector": sparse_vec_list[i],
"dense_vector": dense_vectors[i],
}
)
if data_to_insert:
result = milvus_client.insert(collection_name=COLLECTION_NAME, data=data_to_insert)
print(f"成功插入 {result['insert_count']} 条数据。")
# 6. 创建索引
print("--> 正在为新集合创建索引...")
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="HNSW",
metric_type="COSINE",
params={"M": 16, "efConstruction": 256},
)
milvus_client.create_index(collection_name=COLLECTION_NAME, index_params=index_params)
# 为稀疏向量创建索引
sparse_index_params = milvus_client.prepare_index_params()
sparse_index_params.add_index(
field_name="sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
)
milvus_client.create_index(
collection_name=COLLECTION_NAME, index_params=sparse_index_params
)
print("稀疏向量索引创建成功。")
dense_index_params = milvus_client.prepare_index_params()
dense_index_params.add_index(
field_name="dense_vector",
index_type="AUTOINDEX",
metric_type="IP",
)
milvus_client.create_index(
collection_name=COLLECTION_NAME, index_params=dense_index_params
)
print("密集向量索引创建成功。")
# 7. 创建查询向量
query_image_path = os.path.join(DATA_DIR, "dragon", "query.png")
query_text = "悬崖上的巨龙"
query_img_embeddings = encoder.encode_image(img_path=query_image_path)
query_text_embeddings = ef([query_text])
dense_vec = query_img_embeddings
sparse_vec = query_text_embeddings["sparse"]
# 打印向量信息
print("\n=== 向量信息 ===")
print(f"密集向量维度: {len(dense_vec)}")
print(f"密集向量前5个元素: {dense_vec[:5]}")
print(f"密集向量范数: {np.linalg.norm(dense_vec):.4f}")
print(f"\n稀疏向量维度: {sparse_vec.shape[1]}")
print(f"稀疏向量非零元素数量: {sparse_vec.nnz}")
print("稀疏向量前5个非零元素:")
for i in range(min(5, sparse_vec.nnz)):
print(f" - 索引: {sparse_vec.indices[i]}, 值: {sparse_vec.data[i]:.4f}")
density = sparse_vec.nnz / sparse_vec.shape[1] * 100
print(f"\n稀疏向量密度: {density:.8f}%")
# 8. 搜索
milvus_client.load_collection(collection_name=COLLECTION_NAME)
top_k = 5
# 定义搜索参数
search_params = {"metric_type": "IP", "params": {}}
# 先执行单独的搜索
print("\n--- [单独] 密集向量搜索结果 ---")
dense_results = milvus_client.search(
collection_name=COLLECTION_NAME,
data=[dense_vec],
anns_field="dense_vector",
search_params=search_params,
limit=top_k,
# expr=search_filter,
output_fields=[
"description",
"vector",
"title",
],
)[0]
for i, hit in enumerate(dense_results):
print(f"{i + 1}. {hit.get('title')} (Score: {hit.get('distance'):.4f})")
print("\n--- [单独] 稀疏向量搜索结果 ---")
sparse_results = milvus_client.search(
collection_name=COLLECTION_NAME,
data=[sparse_vec],
anns_field="sparse_vector",
search_params=search_params,
limit=top_k,
# expr=search_filter,
output_fields=[
"vector",
"description",
"title",
],
)[0]
for i, hit in enumerate(sparse_results):
print(f"{i + 1}. {hit.get('title')} (Score: {hit.get('distance'):.4f})")
print("\n--- [混合] 稀疏+密集向量搜索结果 ---")
# 创建 RRF 融合器
rerank = RRFRanker(k=60)
# 创建搜索请求
dense_req = AnnSearchRequest([dense_vec], "dense_vector", search_params, limit=top_k)
sparse_req = AnnSearchRequest([sparse_vec], "sparse_vector", search_params, limit=top_k)
# 执行混合搜索
results = milvus_client.hybrid_search(
collection_name=COLLECTION_NAME,
reqs=[sparse_req, dense_req],
ranker=rerank,
limit=top_k,
output_fields=[
"title",
"description",
"vector",
],
)[0]
# 打印最终结果
for i, hit in enumerate(results):
print(f"{i + 1}. {hit.get('title')} (Score: {hit.get('distance'):.4f})")
# 9. 释放资源
milvus_client.release_collection(collection_name=COLLECTION_NAME)
=== 向量信息 ===
密集向量维度: 768
密集向量前5个元素: [-0.035911474376916885, 0.06154605373740196, -0.06514566391706467, 0.041258905082941055, 0.03218768537044525]
密集向量范数: 1.0000
稀疏向量维度: 250002
稀疏向量非零元素数量: 6
稀疏向量前5个非零元素:
- 索引: 6, 值: 0.0659
- 索引: 7977, 值: 0.1459
- 索引: 14732, 值: 0.2959
- 索引: 31433, 值: 0.1463
- 索引: 141121, 值: 0.1587
稀疏向量密度: 0.00239998%
--- [单独] 密集向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.7908)
2. 中华金龙 (Score: 0.6975)
3. 霸王龙的怒吼 (Score: 0.6592)
4. 驯龙高手:无牙仔 (Score: 0.5703)
5. 金丝猴 (Score: 0.3977)
--- [单独] 稀疏向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.2319)
2. 中华金龙 (Score: 0.0923)
3. 奔跑的奶龙 (Score: 0.0910)
4. 霸王龙的怒吼 (Score: 0.0725)
5. 驯龙高手:无牙仔 (Score: 0.0691)
--- [混合] 稀疏+密集向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.0328)
2. 中华金龙 (Score: 0.0323)
3. 霸王龙的怒吼 (Score: 0.0315)
4. 驯龙高手:无牙仔 (Score: 0.0310)
5. 奔跑的奶龙 (Score: 0.0159)