学习文档地址:第四章 第二、三节
本章的主要内容是介绍查询构建,即将用户的自然语言转为针对特定数据源的结构化查询语言,使得RAG能够无缝利用和对接各种数据类型。
文本到元数据过滤
元数据是我们为文档附加的一些信息,例如标题、作者、简介、发布时间等等,在上一章中,我们看到的drogan.json里面就是附加的元数据;
{
"img_id": "dragon02",
"path": "../../data/C3/dragon/dragon02.png",
"title": "悬崖上的白龙",
"description": "一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。",
"category": "western_dragon",
"location": "悬崖海岸",
"environment": "天空"
},
Langchain中有一个 自查询检索器(Self-Query Retriever) 组件,其工作原理如下,当我们向从龙的图片中查询西方龙时,自查询检索器会将其进行解析:
- 查询语句:“西方龙的图片”
- 元数据过滤器:
category==western_dragon
代码示例
加载数据
这里使用BilibiliLoader来通过URL获取B站视频的基础元数据,包括title author length view_count等;返回的原始的元数据其实很多,但是这里只挑选其中几个来进行示例。
# 1. 初始化视频数据
video_urls = [
"https://www.bilibili.com/video/BV1Bo4y1A7FU",
"https://www.bilibili.com/video/BV1ug4y157xA",
"https://www.bilibili.com/video/BV1yh411V7ge",
]
bili = []
try:
loader = BiliBiliLoader(video_urls=video_urls)
docs = loader.load()
for doc in docs:
original = doc.metadata
print(doc.metadata)
# 提取基本元数据字段
metadata = {
'title': original.get('title', '未知标题'),
'author': original.get('owner', {}).get('name', '未知作者'),
'source': original.get('bvid', '未知ID'),
'view_count': original.get('stat', {}).get('view', 0),
'length': original.get('duration', 0),
}
doc.metadata = metadata
bili.append(doc)
print(f"已加载 {len(bili)} 个视频")
for doc in bili:
print(doc.metadata)
实际元数据
# 输出结果
{'title': '01.课程介绍', 'author': '二次元的Datawhale', 'source': 'BV1Bo4y1A7FU', 'view_count': 45598, 'length': 390}
{'title': '02.Prompt 的构建原则', 'author': '二次元的Datawhale', 'source': 'BV1ug4y157xA', 'view_count': 19066, 'length': 1063}
{'title': '03.Prompt如何迭代优化', 'author': '二次元的Datawhale', 'source': 'BV1yh411V7ge', 'view_count': 7187, 'length': 806}
存入向量数据库
这里使用Chroma数据库进行演示,同时,还需要我们手动配置好各类元数据,包括名称和类型;
存入Chroma的数据是存到了内存中,并没有到磁盘进行永久化。如果想要永久化存储到磁盘,可以使用persist_directory参数指定位置。
# 2. 创建向量存储
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
vectorstore = Chroma.from_documents(bili, embed_model)
# 3. 配置元数据字段信息
metadata_field_info = [
AttributeInfo(
name="title",
description="视频标题(字符串)",
type="string",
),
AttributeInfo(
name="author",
description="视频作者(字符串)",
type="string",
),
AttributeInfo(
name="view_count",
description="视频观看次数(整数)",
type="integer",
),
AttributeInfo(
name="length",
description="视频长度(整数)",
type="integer"
)
]
构建查询
这里笔者使用本地的qwen3:8b模型进行查询,在构建自查询检索器时,要提供给它向量数据库、llm、文档的元数据信息等;
llm = ChatOllama(model="qwen3:8b", base_url="http://localhost:11434")
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vectorstore,
document_contents="记录视频标题、作者、观看次数等信息的视频元数据",
metadata_field_info=metadata_field_info,
enable_limit=True,
verbose=True
)
执行查询
# 5. 执行查询示例
queries = [
"时间最短的视频",
"时长大于600秒的视频"
]
for query in queries:
print(f"\n--- 查询: '{query}' ---")
results = retriever.invoke(query)
if results:
for doc in results:
title = doc.metadata.get('title', '未知标题')
author = doc.metadata.get('author', '未知作者')
view_count = doc.metadata.get('view_count', '未知')
length = doc.metadata.get('length', '未知')
print(f"标题: {title}")
print(f"作者: {author}")
print(f"观看次数: {view_count}")
print(f"时长: {length}秒")
print("="*50)
else:
print("未找到匹配的视频")
代码结果
--- 查询: '时间最短的视频' ---
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】03.Prompt如何迭代优化
作者: 二次元的Datawhale
观看次数: 7187
时长: 806秒
==================================================
--- 查询: '时长大于600秒的视频' ---
filter=Comparison(comparator=<Comparator.GT: 'gt'>, attribute='length', value=600) limit=None
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】02.Prompt 的构建原则
作者: 二次元的Datawhale
观看次数: 19066
时长: 1063秒
==================================================
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】03.Prompt如何迭代优化
作者: 二次元的Datawhale
观看次数: 7187
时长: 806秒
==================================================
思考
为什么本节的代码中查询“时间最短的视频”时,得到的结果是错误的?
从一开始的输出中,我们可以看到,时长最短的应该是第一个视频,它的length只有390,但是在查询中,返回的是第三个视频,时长是806秒;
元数据和查询语句的不匹配。
在查询语句中,询问的是时间最短的视频,但是在元数据中,并没有时间这个属性,只有视频长度和视频观看次数,所以检索器无法从元数据中准确提取到底需要查询哪个。
自检索查询的核心就是去“理解”和“推断”出查询中隐含的元数据过滤条件,并自动构建一个结构化的查询。如果查询语句中没有与元数据相关的信息,他就会退化成一个普通的向量检索器,纯粹进行语义搜索,不在对元数据进行任何过滤;
综上,如果想要获得时间最短的视频,有两种方式:
- 修改查询语句 -->
视频长度最短的视频 - 修改元数据描述 -->
视频时间长度,单位为秒(整数),数值越小表示视频越短
这样,LLM就可以正确查询出结果了
--- 查询: '视频时长最短的视频' ---
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】01.课程介绍
作者: 二次元的Datawhale
观看次数: 45598
时长: 390秒
==================================================
文本到SQL
作为分析师,SQL是离不开的,如何能让自然语言转为正确的SQL一直是行业内的老大难问题,LLM无法正确理解用户的输入信息,无法找到其想要的表、字段,也就无法输出正确的SQL,更不用说复杂的多表联合查询了。
优化思路
- 提供精确的
DDL,即数据库、数据表的全部信息,包括字段、类型、描述、主键、索引等,这样LLM能够很清楚的了解这些关系,以及如何处理; - 提供少量示例,能够极大的提升LLM输出准确率,范例=高质量先验+结构化模板+任务边界,它们把抽象规则压缩成可直接模仿的模式,从而显著降低 LLM 的搜索空间与歧义。
- 利用RAG增强上下文,提供更多业务逻辑信息给到LLM,在查询前可以获得更多信息。
- 利用错误信息,让它“反思”并修正SQL语句,然后重试,这个迭代过程可以显著提高查询的成功率。
开源项目
WrenAI
Canner/WrenAI: ⚡️ GenBI (Generative BI)是一个开源的GenBI(生成式商业智能)代理,通过自然语言查询数据库,将用户问题转换为准确的SQL查询并生成可视化图表,解决了非技术用户难以直接查询数据库的问题。 WrenAI提供四个主要功能:
- Text-to-SQL: 将自然语言问题转换为准确的SQL查询;
- Text-to-Charts: 从自然语言请求生成数据可视化图表;
- 语义层: 通过MDL(模型定义语言)进行模式治理;
- 多数据库支持: 跨不同数据库系统查询,支持BigQuery、PostgreSQL、Snowflake、DuckDB等10多种数据源;
SQLBot
dataease/SQLBot: 基于大模型和 RAG 的智能问数系统是由国产开源团队dataease出品的基于大模型和 RAG 的智能问数系统。
SQLBot 的优势包括:
- 开箱即用: 只需配置大模型和数据源即可开启问数之旅,通过大模型和 RAG 的结合来实现高质量的 text2sql;
- 易于集成: 支持快速嵌入到第三方业务系统,也支持被 n8n、MaxKB、Dify、Coze 等 AI 应用开发平台集成调用,让各类应用快速拥有智能问数能力;
- 安全可控: 提供基于工作空间的资源隔离机制,能够实现细粒度的数据权限控制。
NL2SQL_HANDBOOK
HKUSTDial/NL2SQL_Handbook是一个关于自然语言转SQL(NL2SQL)的综合性手册,主要内容包括对NL2SQL技术的全面调研和实用指南。 项目提供了丰富的研究资源,非常值得学习:
- 全面的论文列表和基准测试数据集;
- 评估工具和指标;
- 实用的新手指南;
大模型榜单
-
BIRD-CRITIC首个 SQL 诊断基准,该基准包含 600 个用于开发的任务和 200 个分布外(OOD)测试。BIRD-CRITIC 1.0 基于 4 种主要的开源 SQL 语言(MySQL、PostgreSQL、SQL Server 和 Oracle)中的真实用户问题构建:它超越了简单的 SELECT 查询,涵盖了更广泛的 SQL 操作,反映了实际应用场景。最后,包含了一个优化的基于执行的评估环境,用于严格且高效的验证。
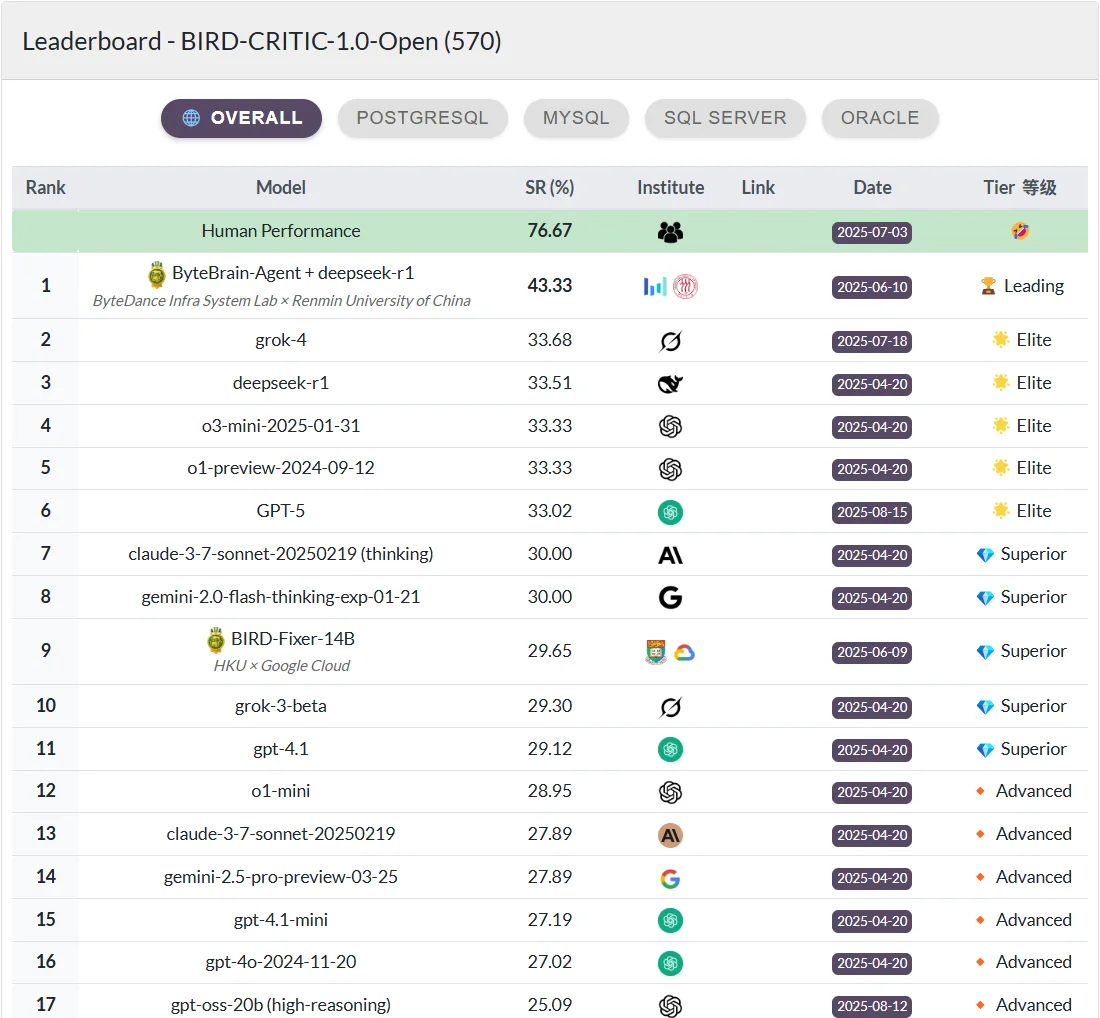
-
BIRD-bench推进文本到 SQL 的训练技术,并实现单个模型能力的公平比较。这榜单也是Bird的,主要用来评比单个模型的SQL能力;