学习文档地址:第四章 第五节
在RAG(检索增强生成)技术中,有几种比较高级的检索方式,它们旨在提高检索的准确性和效率,从而改善生成模型的输出质量。
查询构建
这是检索过程的起始点,涉及到如何将用户的问题转化为有效的检索查询。
- Text-to-SQL/Cypher/VectorDBs: 这种方式将自然语言问题转化为特定数据库(如关系型数据库的SQL,图数据库的Cypher,或向量数据库的自查询检索器)的查询语言。例如,自查询检索器可以根据查询自动过滤元数据。
查询翻译
并不是从英文翻译到中文这样,而是在将查询发送到检索系统之前,进行预处理以优化其形式。
提示工程
通过提示词让LLM将用户的查询输入改写的更加具体清晰,例如在上节中,可以通过提示词,让LLM输出JSON格式:
# 使用大模型将自然语言转换为排序指令
prompt = f"""你是一个智能助手,请将用户的问题转换成一个用于排序视频的JSON指令。
你需要识别用户想要排序的字段和排序方向。
- 排序字段必须是 'view_count' (观看次数) 或 'length' (时长) 之一。
- 排序方向必须是 'asc' (升序) 或 'desc' (降序) 之一。
例如:
- '时间最短的视频' 或 '哪个视频时间最短' 应转换为 {{"sort_by": "length", "order": "asc"}}
- '播放量最高的视频' 或 '哪个视频最火' 应转换为 {{"sort_by": "view_count", "order": "desc"}}
请根据以下问题生成JSON指令:
原始问题: "{query}"
JSON指令:"""
Multi-query (多查询)
生成多个查询以捕获问题的不同方面,将用户的一个输入拆解为多个更简单的子问题; 示例:
- 原始问题:“在《流浪地球》中,刘慈欣对人工智能和未来社会结构有何看法?”
- 分解后的子问题:
- “《流浪地球》中描述的人工智能技术有哪些?”
- “《流浪地球》中描绘的未来社会是怎样的?”
- “刘慈欣关于人工智能的观点是什么?”
退步提示(Step-Back Prompting)
是一种通过逆向推理链来提升大模型复杂问题解决能力的提示工程技术。其核心思想是引导模型从问题的终点反向分解步骤,最终定位初始条件或解决方案。 示例:
- 原始提问: "为什么我搜索'适合夏天穿的透气运动鞋'却看不到合适的凉鞋?"
- 分解后:
1. [最终目标] 用户需要"夏季透气鞋类"(不限于运动鞋)
2. [当前问题] 为什么凉鞋未被召回?
- 可能原因A:检索系统严格限定"运动鞋"类别
- 可能原因B:凉鞋未标注"透气"属性
- 可能原因C:向量空间未对齐"凉鞋-透气"关系
3. [前一步] 如何发现这些原因?
- 验证A:检查商品分类规则(发现:用户搜索词强制过滤"运动鞋"类)
- 验证B:分析凉鞋属性标签(发现:80%凉鞋标注"透气")
- 验证C:测试"凉鞋"与"透气"的向量相似度(发现:cos=0.3,低于阈值0.5)
4. [系统初始设计] 为什么会有这些问题?
- 问题A:历史搜索日志显示用户更常搜索"运动鞋"
- 问题B:商品标注指南未强调"透气"属性
- 问题C:嵌入模型未针对季节性词汇优化
假设性文档嵌入 (HyDE)
假设性文档嵌入(Hypothetical Document Embeddings, HyDE)是一种无需微调即可显著提升向量检索质量的查询改写技术,原理就是:先利用一个生成式大语言模型(LLM)来生成一个“假设性”的、能够完美回答该查询的文档。然后,HyDE 将这个内容详实的假设性文档进行向量化,用其生成的向量去数据库中寻找与之最相似的真实文档。
类比:就像侦探先根据案情推测凶手特征(假设文档),再比对此特征查找真实嫌疑人(真实案例),而非仅根据报案人口述(原始查询)盲目搜索。
查询路由
一种由大语言模型(LLM)支持的决策步骤,用于确定针对用户查询接下来应采取的最佳行动。这个过程可以被看作是一种智能的查询分发功能,根据用户输入的语义内容从多个处理方法或数据源中选择最合适的选项。
- 用户提问:“你们的退货政策是什么?”
- 路由器分析这个问题,识别出它属于“公司政策”类别。
- 它决定最佳行动是查询FAQ向量数据库,因为这类信息通常存储在非结构化的文档中。
- 系统从FAQ库中检索相关信息,并生成回答。
重排序(Re-Ranking)
RRF
在混合检索中已经提过了RRF,核心是基于文档在多个不同检索器(例如,一个稀疏检索器和一个密集检索器)结果列表中的排名来计算最终分数。 但是也通过实际代码发现,有些时候混合检索的排名并不能很好的匹配实际情况。
RankLLM
一句话概括就是:直接让LLM来判断这些文档与查询语句的相关情况,让它直接来评分。
Cross-Encoder 重排
Cross-Encoder是一种深度交互匹配模型,其核心特点是:
- 联合编码:将查询(Query)和文档(Document)拼接成一个序列,通过Transformer等模型直接计算相关性分数
- 全交互注意力:允许Query和Document的所有token直接交互(如BERT的
[CLS]query[SEP]doc[SEP]结构) 借助另外的模型去判断文档与查询的相关性。
压缩(Compression)
压缩的目标就是对检索到的内容进行“压缩”和“提炼”,只保留与用户查询最直接相关的信息。两种主要方式实现:
- 内容提取:从文档中只抽出与查询相关的句子或段落。
- 文档过滤:完全丢弃那些虽然被初步召回,但经过更精细判断后认为不相关的整个文档。
校正 (Correcting)
在生成答案之前,对检索到的文档质量进行评估,并根据评估结果采取不同的行动,避免检索到错误的文章而导致整个回答错误。
- 检索 (Retrieve) :与标准 RAG 一样,首先根据用户查询从知识库中检索一组文档。
- 评估 (Assess) :这是 C-RAG 的关键步骤。如图所示,一个“检索评估器 (Retrieval Evaluator)”会判断每个文档与查询的相关性,并给出“正确 (Correct)”、“不正确 (Incorrect)”或“模糊 (Ambiguous)”的标签。
- 行动 (Act) :根据评估结果,系统会进入不同的知识修正与获取流程:
- 如果评估为“正确”:系统会进入“知识精炼 (Knowledge Refinement)”环节。它会将原始文档分解成更小的知识片段 (strips),过滤掉无关部分,然后重新组合成更精准、更聚焦的上下文,再送给大模型生成答案。
- 如果评估为“不正确”:系统认为内部知识库无法回答问题,此时会触发“知识搜索 (Knowledge Searching)”。它会先对原始查询进行“查询重写 (Query Rewriting)”,生成一个更适合搜索引擎的查询,然后进行 Web 搜索,用外部信息来回答问题。
- 如果评估为“模糊”:同样会触发“知识搜索”,但通常会直接使用原始查询进行 Web 搜索,以获取额外信息来辅助生成答案。
练习
在“自定义重排器与压缩管道”部分的代码中,运行结果会输出重排后的语句有重复部分,如下图:
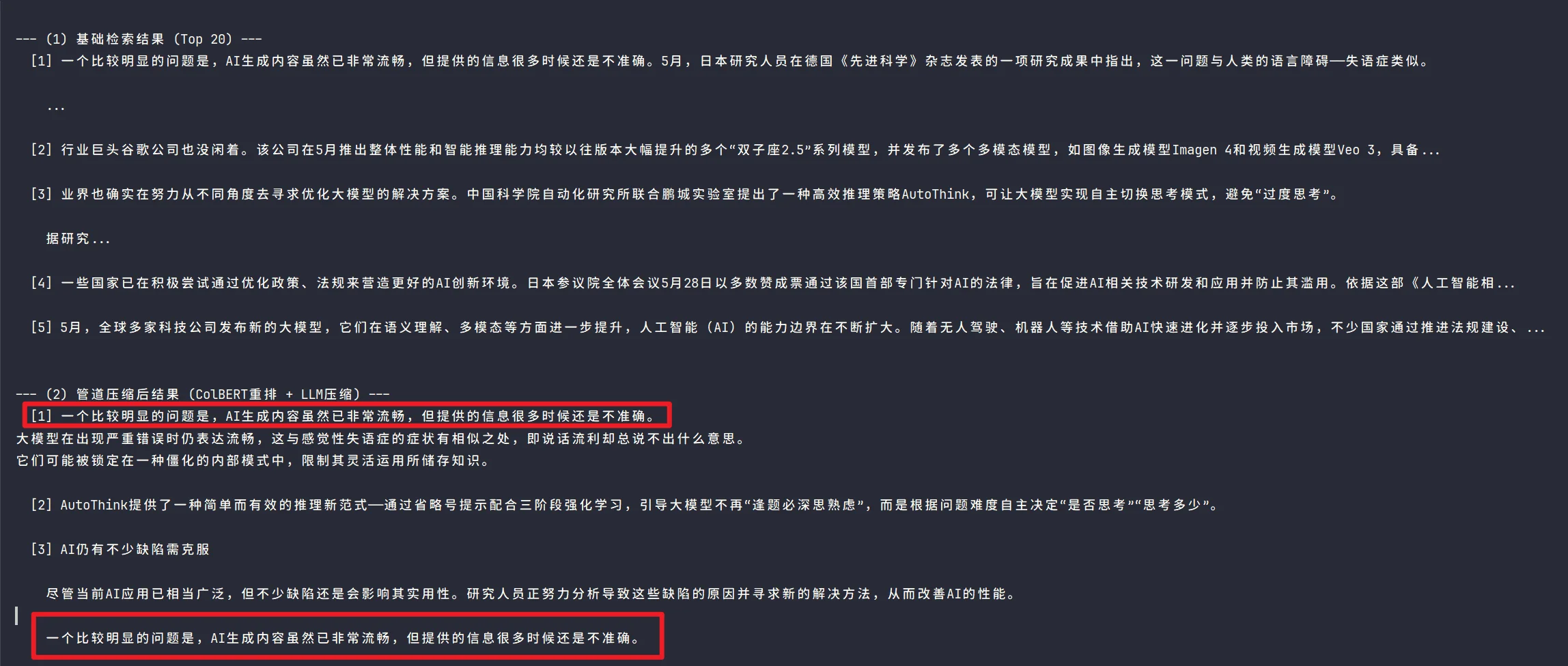
文本分块导致有重复。
其实可以看出,重复的是第一句,它处于两个chunk的重合部分,也就是我们在笔记第三节所提到的文本分块的内容。在前面代码中,可以看到他的分块参数
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
这里,chunk_size是500,chunk_overlap是100,造成了上面这种重复的问题。如果可以适当减小下overlap的值,就不会有重复了。下面是我将overlap修改为 50 之后的输出结果。
